

Performance of OSU INAM with MySQL, InfluDB, and ClickHouse as Database Options
The figures and experiments are published at Bench Conference. To learn more please refer to the following publication:
Machine Specifications
| CPU Model | CPU Core Info | Memory | Network Adapter | Switch | OS | Network Stack |
|---|---|---|---|---|---|---|
| Intel Xeon-8280 | 2x28 @ 2.7GHz | 125GB | Mellanox ConnectX-6 (100Gbps) | Mellanox HDR IB Switch | CentOS 7.8.2003 | Mellanox OFED-Internal-5.1-2.3.7 |
Experiments Description
All assessments are made based on 50k rows of data for InfiniBand Port Counter (PC), InfiniBand Port Errors (PE), and MPI counters unless otherwise specified. This is because that is the amount of data that would be generated on a system the size of Frontera with 8,368 compute nodes, 22,819 links, and 448,448 core. The following terminologies are defined and used for the figures:
Databases: CH (ClickHouse), MS (MySQL), FLX (InfluxDB)
Operations: R (Read query), W (Insert query)
Tables: PC (IB Port Counters), PE (IB Port Errors), MPI (MPI process info)
Experiment Considerations
The purpose of this study is to provide a better understanding of the performance interplay between write batch size, multi-threading, and multi-table data access for HPC profiling data with a scale of exascale HPC systems. We assessed the performance of inserting 50,000 rows of IB port counters and errors per second using our benchmarks, chosen as it’s twice the links and nodes of systems like Frontera with 8,368 nodes and 22,819 links.
In the evaluation of read queries, we utilized real-world HPC profiling queries to collect metrics from various tables. All queries monitor HPC system failures, sending alerts to admins or users, and assess job performance at InfiniBand and MPI levels using aggregation and time/node/jobid filters. To evaluate worst-case performance scenarios from the tool’s user perspective, we took the maximum latency among all readers if the read query involves reading from more than a single table (such as port counters and errors) with multiple readers scenarios. This approach emulates the behavior of loading a page and reading data from various tables. By simulating this real-world scenario, our evaluation provides a practical assessment of the performance of database options.
In the multi-table multi-process read/write evaluation, we stopped scaling the experiment if the latency of writing profiling data exceeded 90 seconds, as this is not a desirable database performance to deploy for the tool due to low fidelity profiling. Similarly, if the latency of both reading and writing exceeded 120 seconds, we also stopped the experiment from scaling as it is clear that the performance would be worse. This was done to ensure that the database performance remained within acceptable limits. Our results provide insights into the optimal configurations for handling large-scale data and optimizing database performance in HPC systems.
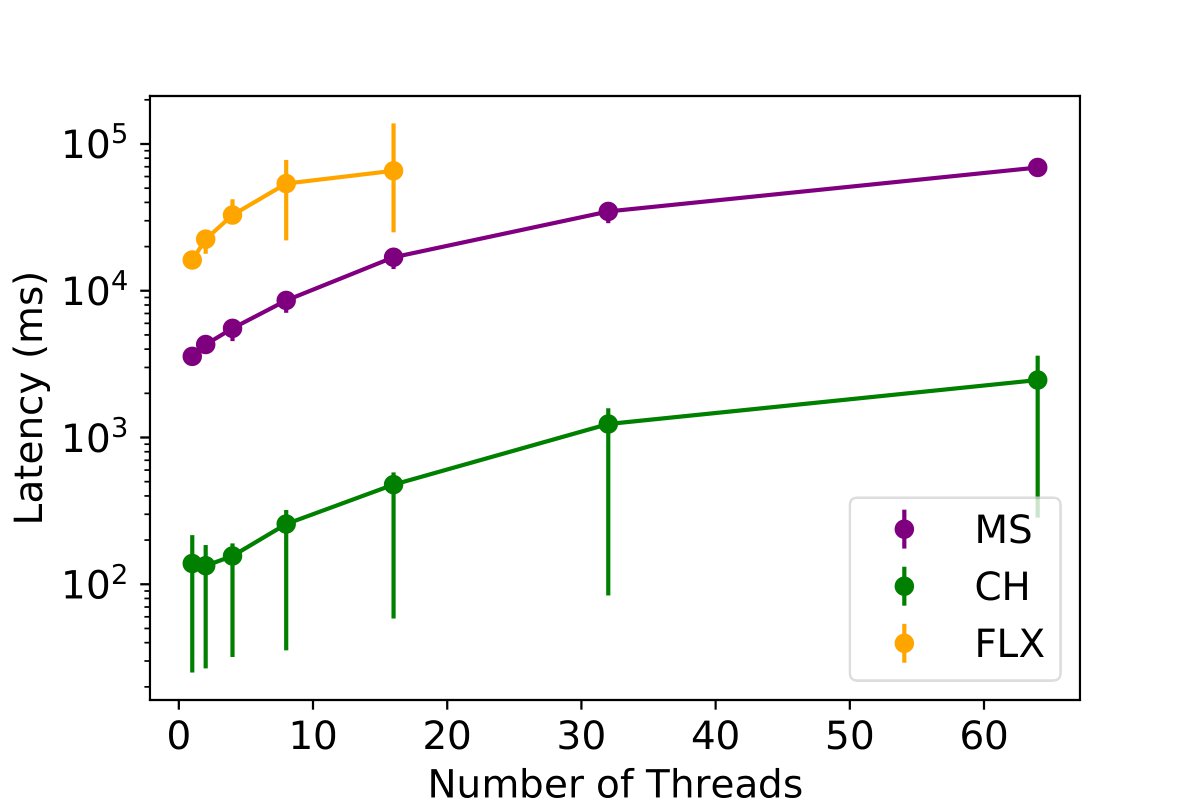
Impact of Parallelism on Data Insertion in INAM
The experiment is designed around a fixed dataset of 200,000 rows for PE and PC data, which is evenly distributed across writer threads ranging from 1 to 16 per table. To simulate a realistic scenario, 16 concurrent readers are added for each table.
The results indicate a substantial performance improvement when utilizing multiple writers. Specifically, employing 16 writers led to a speed-up factor of 9x for ClickHouse, 5x for MySQL, and 3x for InfluxDB. This enhancement was notable in ClickHouse, which exhibited a latency of only 55ms.
Key Findings: These results show that the use of multiple writers can enhance the efficiency of inserting communication profiling data into databases.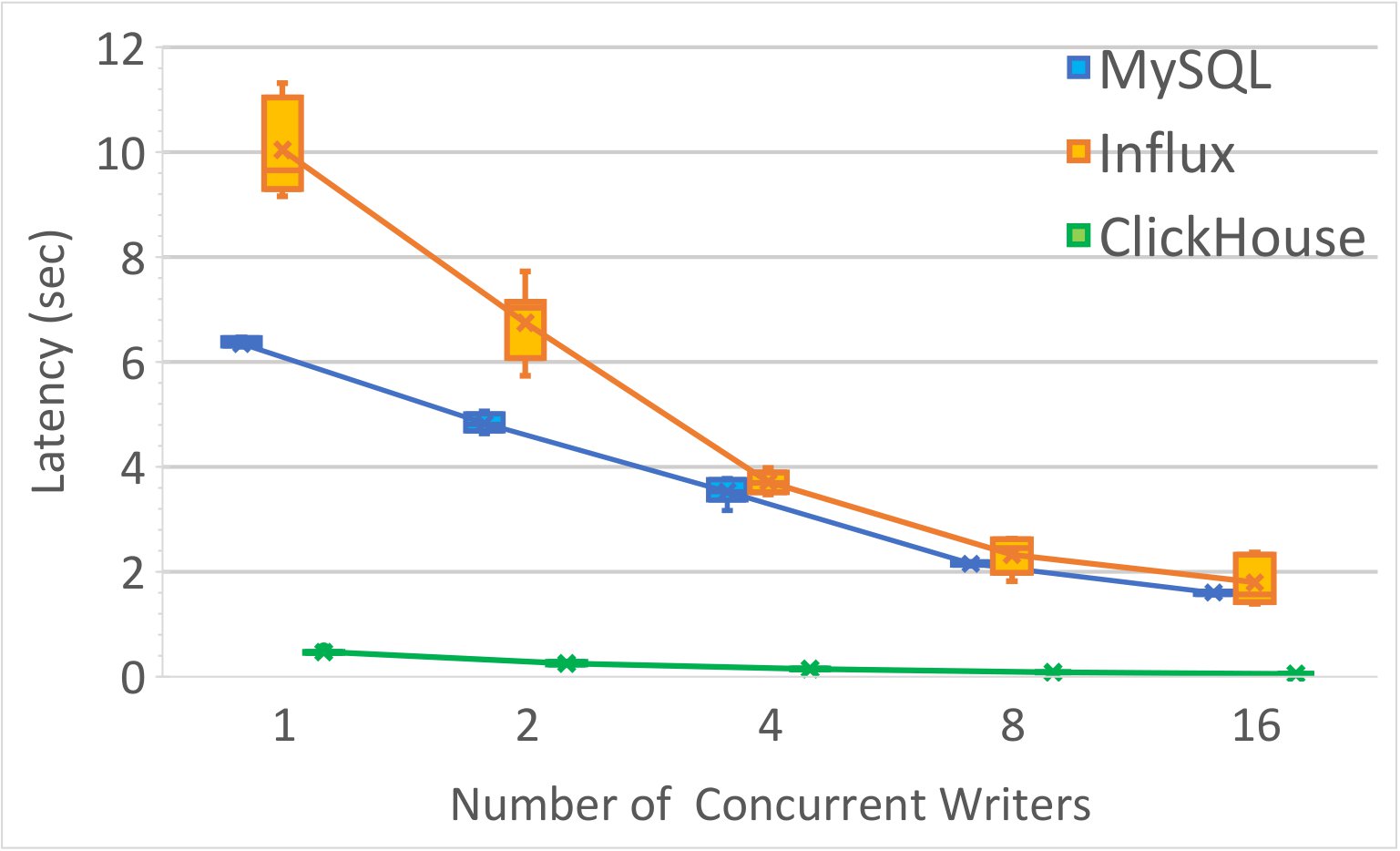
Impact of Batching Rows on Data Insertion Performance
This experiment investigates the impact of batched inserts on different table write performances across various databases and assesses the potential impact of concurrent read queries on this performance. The batch size is systematically varied from 200 to 30,000 rows for each MPI, PE, and PC table, to insert a total of 50,000 rows per table. The duration required to insert the complete dataset into the databases is measured for a single writer process, with the results presented in the following figures. The findings suggest that an increase in batch size generally leads to a decrease in data insertion latency across the databases. However, an exception is observed in MySQL, which displays diminished performance for PE and MPI tables when the batch size exceeds 1,000 rows.
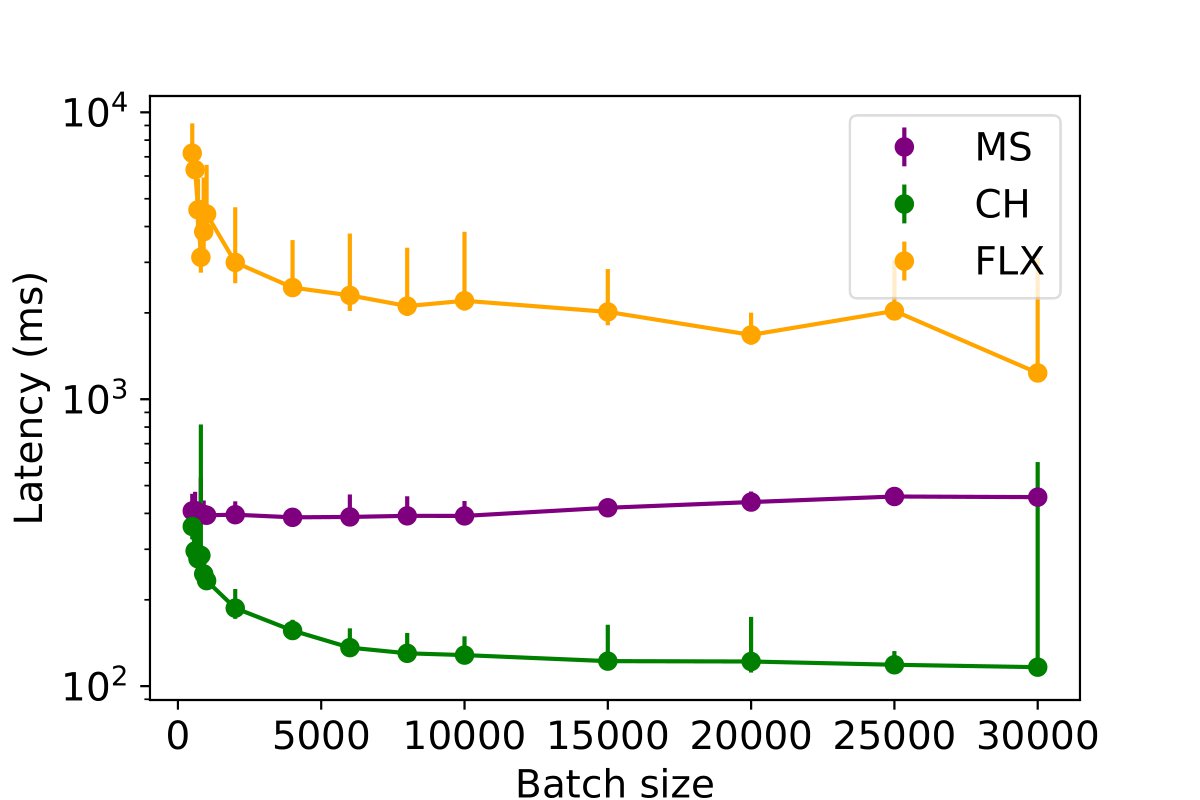
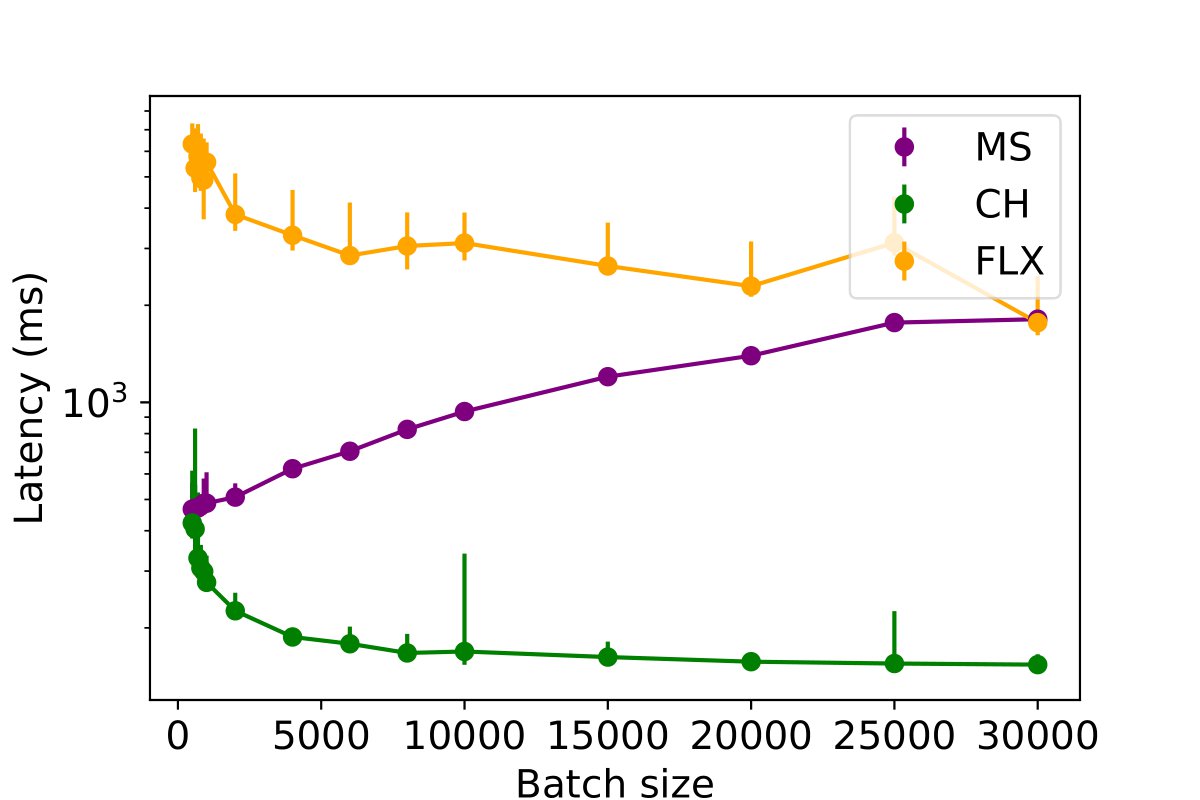
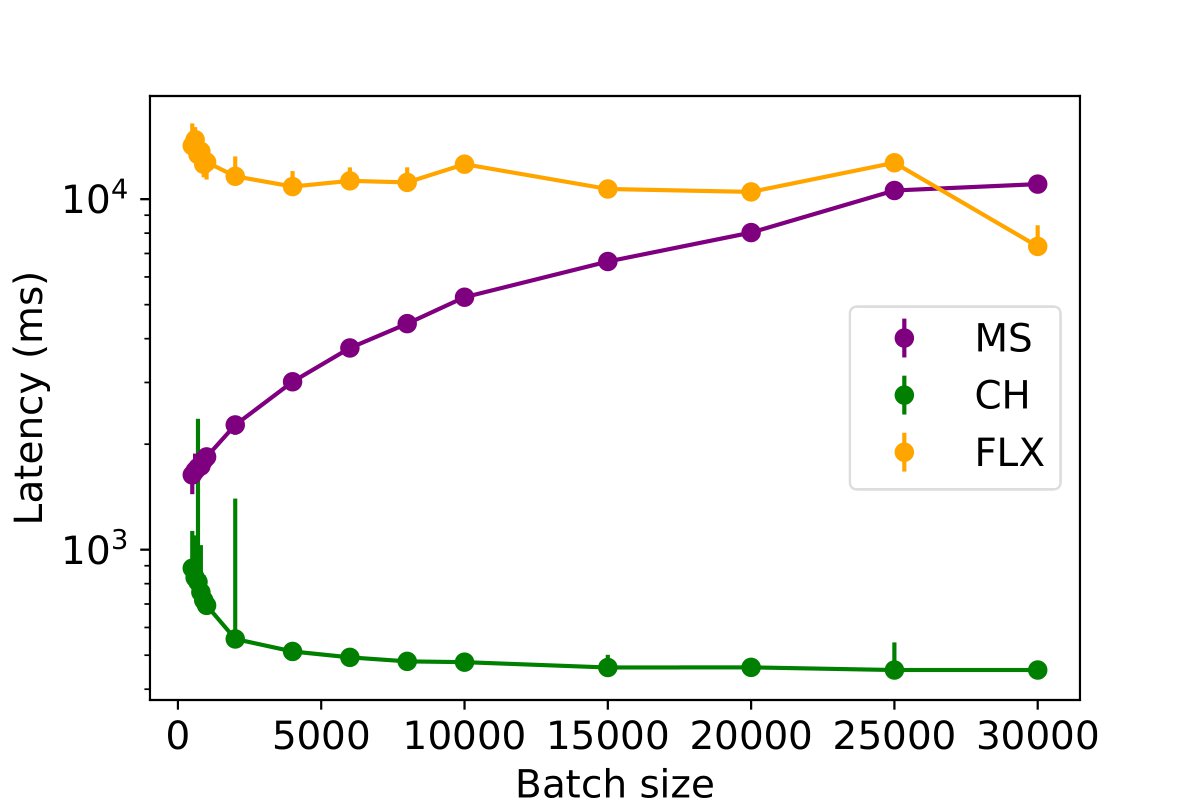
To further assess the influence of batch size, the experiment was replicated with the inclusion of a single reader process, as illustrated in the following figures. The findings indicate that increasing the batch size continues to enhance performance for ClickHouse and InfluxDB. However, for MySQL, surpassing a batch size of 1,000 results in a decline in write performance. Although there is a slight increase in insertion latency when including a reader thread (by approximately 5%), the overall performance remains largely unaffected.
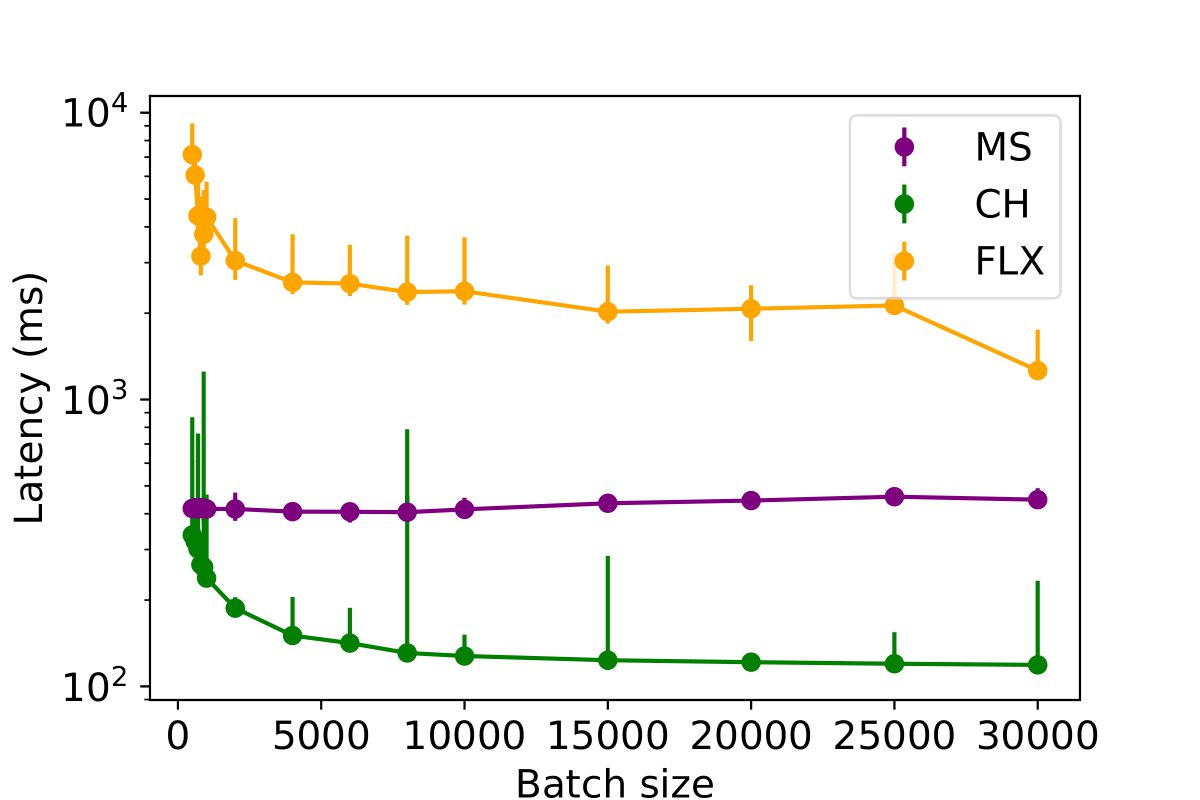
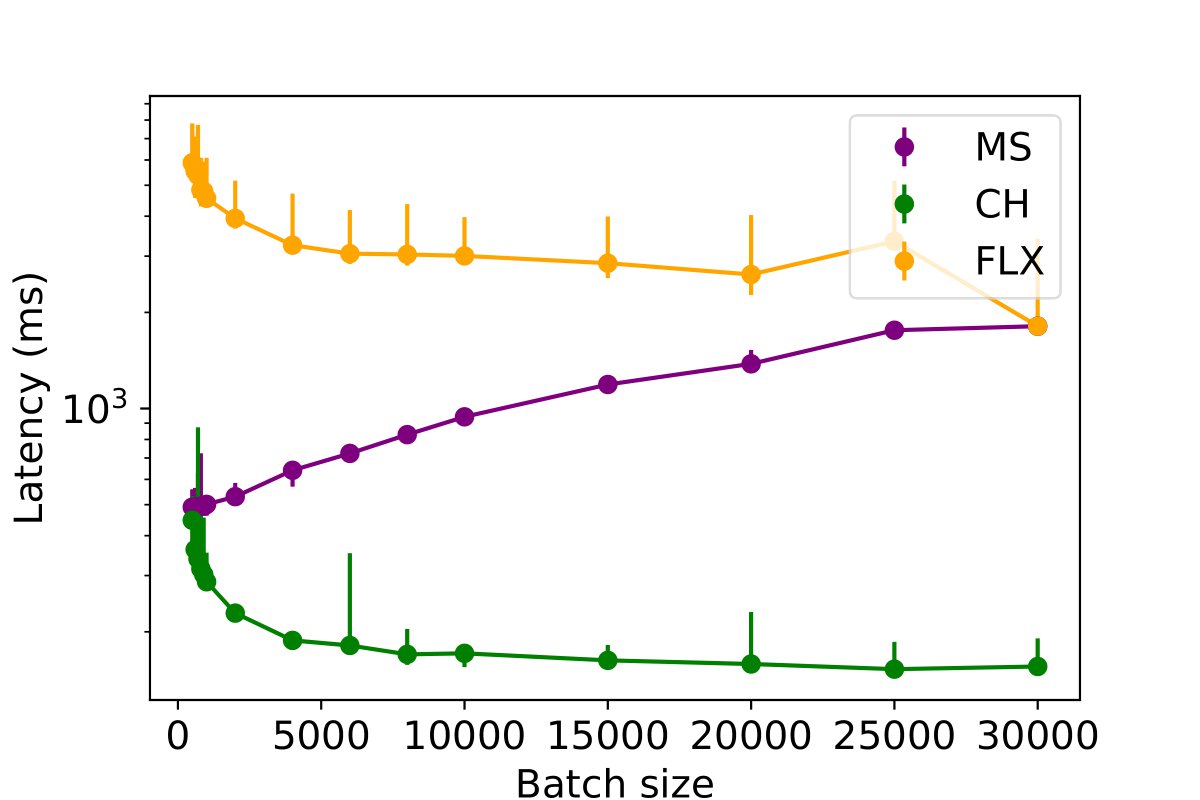
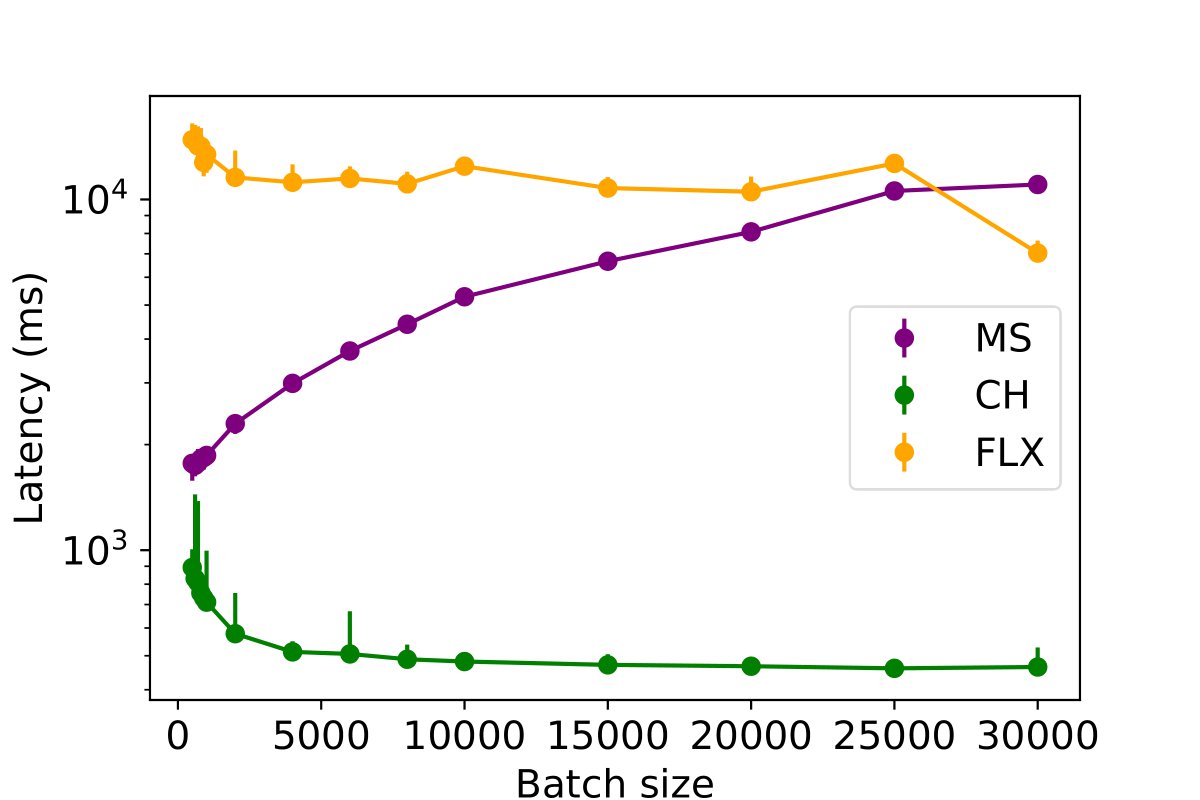
Impact of Scaling The Profiling Data Using Optimal Batch Size
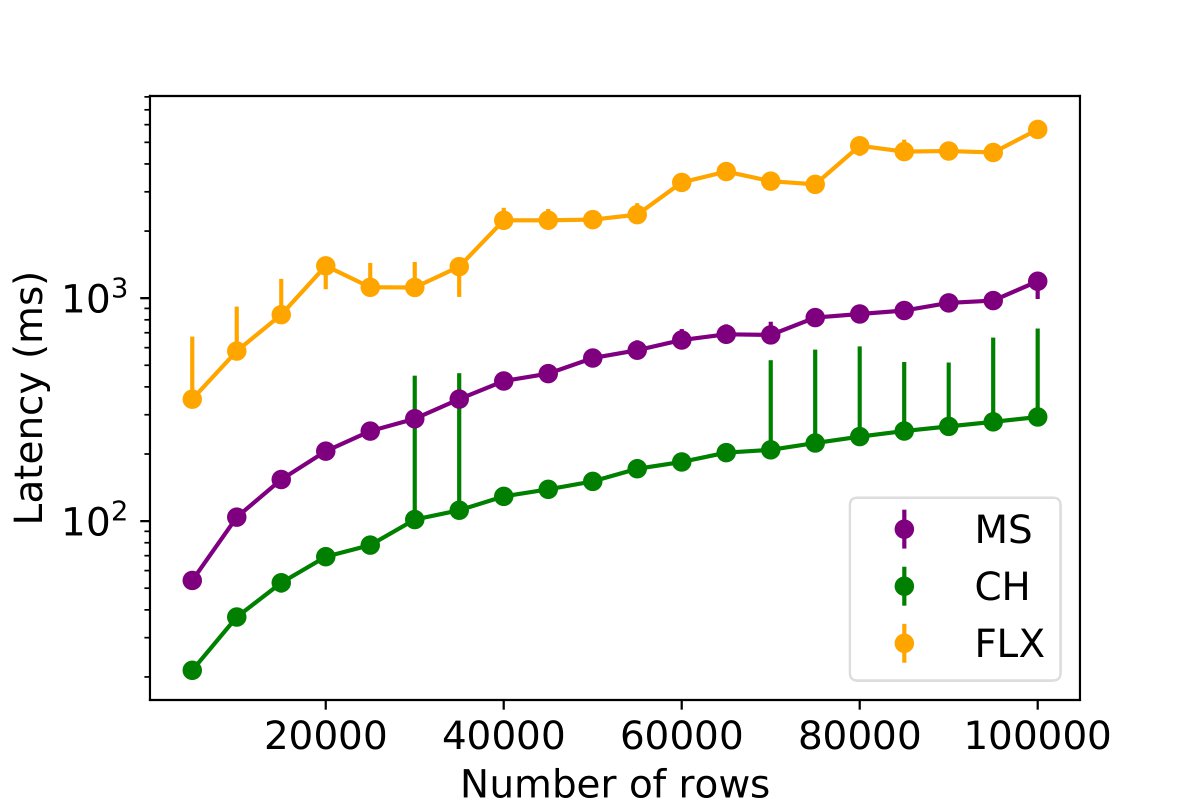
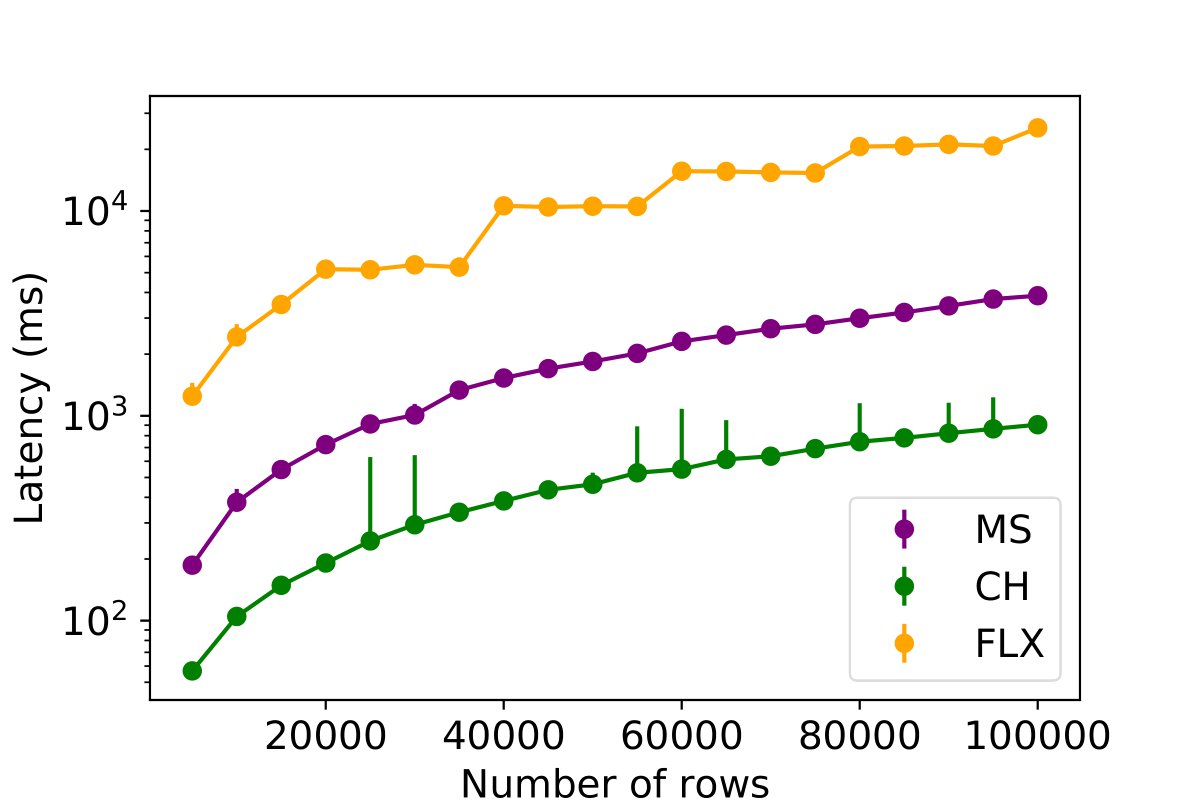
This experiment investigates the impact of varying the number of inserted rows on the performance of three different databases while using the optimized batch sizes per database. The objective of this experiment is to ascertain how the performance of databases storing communication profiling data is affected when the number of rows for each table is scaled. For this purpose, the number of rows designated for insertion is varied from 5,000 (equivalent to the OSC cluster size) to 100,000 (4x the size of Frontera) in each database. The below figures illustrate the insertion latency for each database and table, thereby demonstrating the impact of the number of rows on database performance.
Key Findings: This experiment shows latency under different profiling load for INAM. ClickHouse exhibits superior performance when scaling the number of rows for insertion, albeit with more variation. MySQL, on the other hand, delivers more stable performance. InfluxDB presents a stepped performance pattern, where performance remains consistent up to a certain point, then jumps upon increasing the volume of insertion data.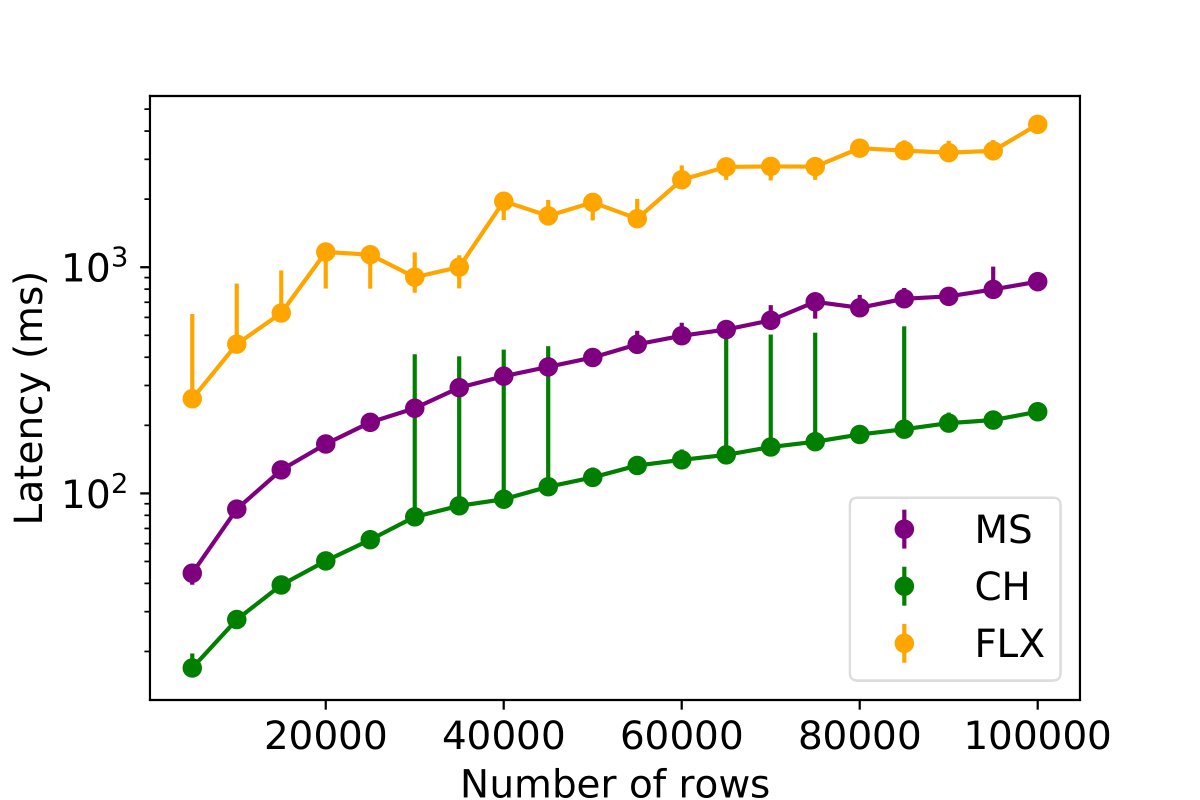
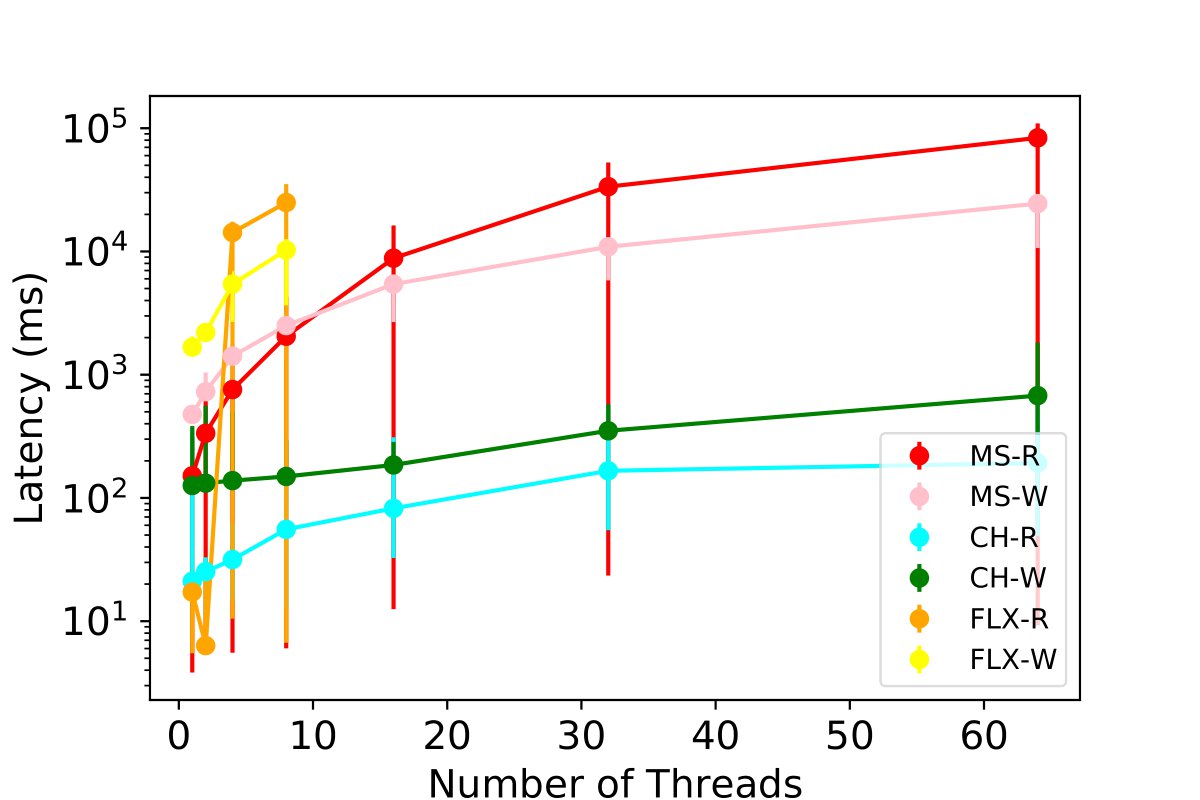
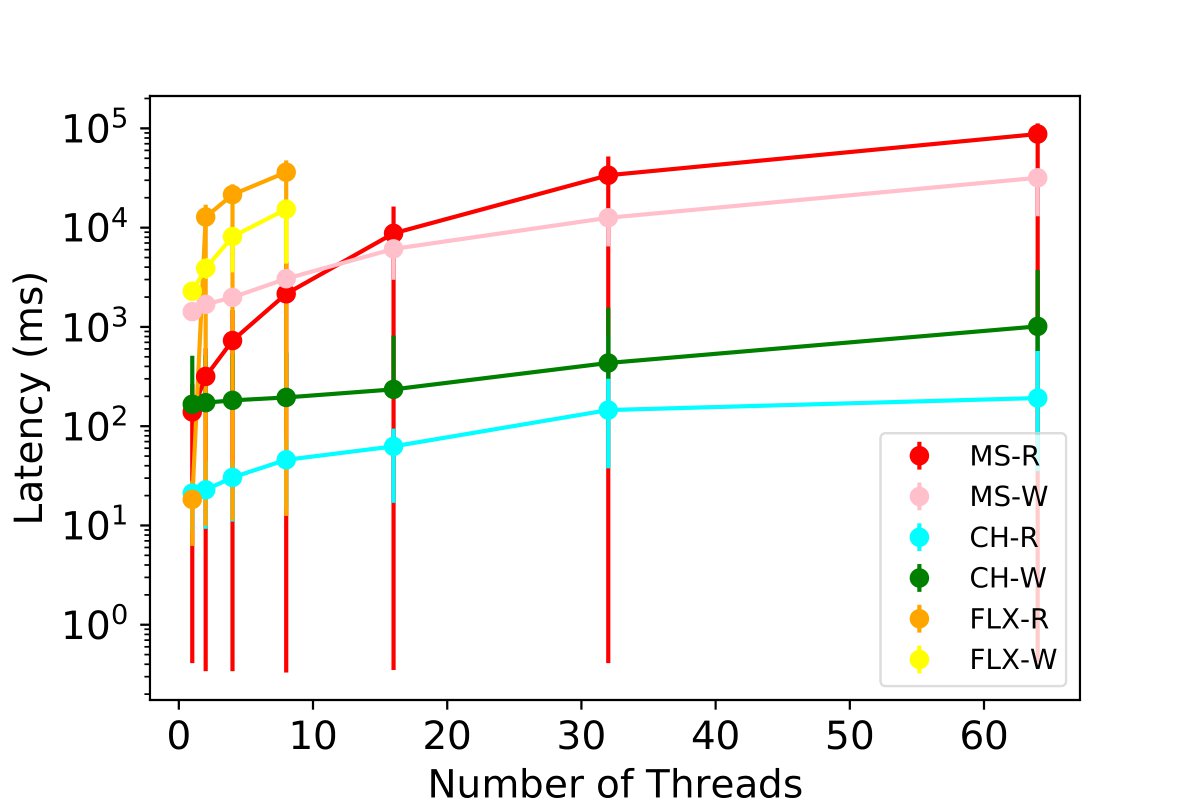
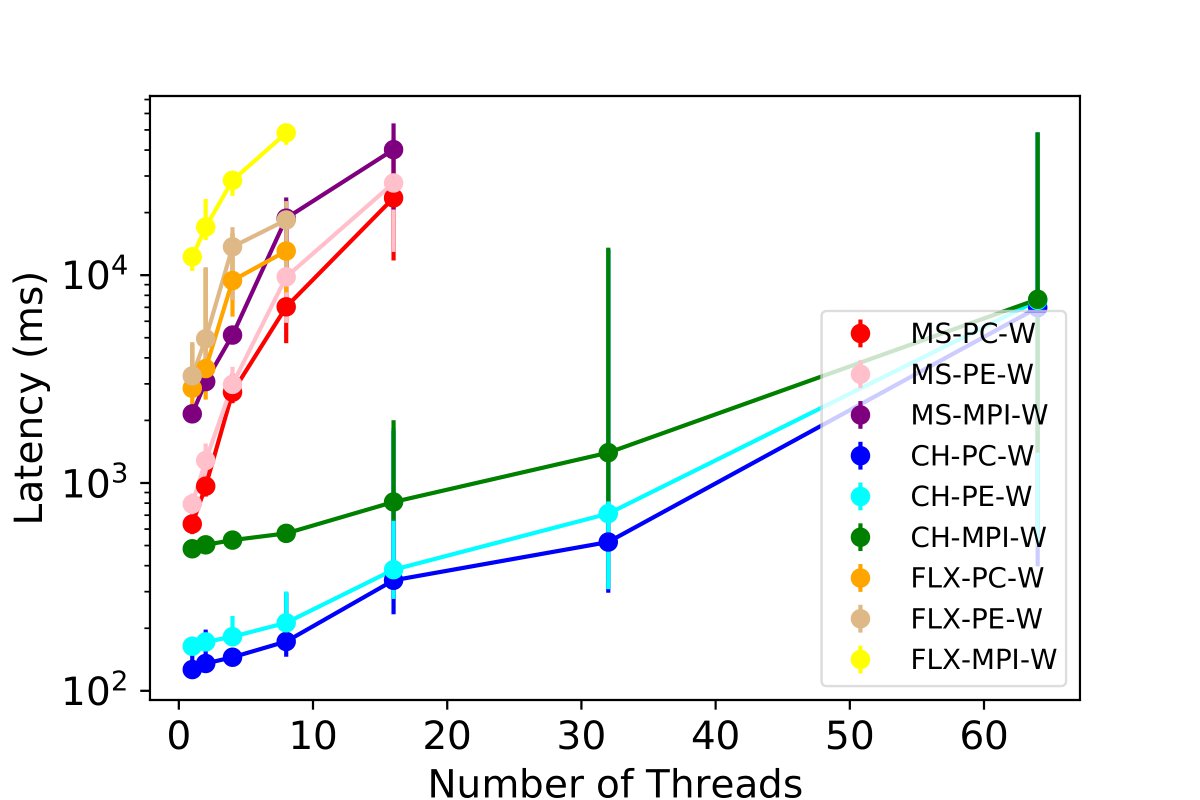
Scaling Simultaneous Insertion and Querying Processes
We test the performance of combinations for three tables - MPI, PE, and PC - under a worst-case scenario where all threads of each table are simultaneously reading and inserting the same volume of data. We scale the number of simultaneous readers and writers, and we monitor the insertion latency for 50,000 rows per thread to each table while concurrently querying. This experiment includes the stress test where multiple users are leveraging the profiling tool at the same time of insertion across all tables.
Our results, presented in the figures below and 9c, show that ClickHouse outperforms all other database options. It demonstrates the ability to scale up to 64 users, inserting 50,000 data points with sub-second granularity. We observe that Clickhouse simultaneously enables 32 threads writing and reading to all the tables and achieves a latency of 2.3 seconds. Some experiments for InfluxDB and MySQL with 64 threads R/W for each table were not carried out due to poor performance exceeding 120 seconds, and the maximum value among all threads were used for read operations.
Key Findings: ClickHouse appears more suitable for exascale HPC profiling with sub-second granularity and concurrent read operations promoting support for more simultaneous users.
Total latency involved with reading or writing certain information across all threads and different tables.
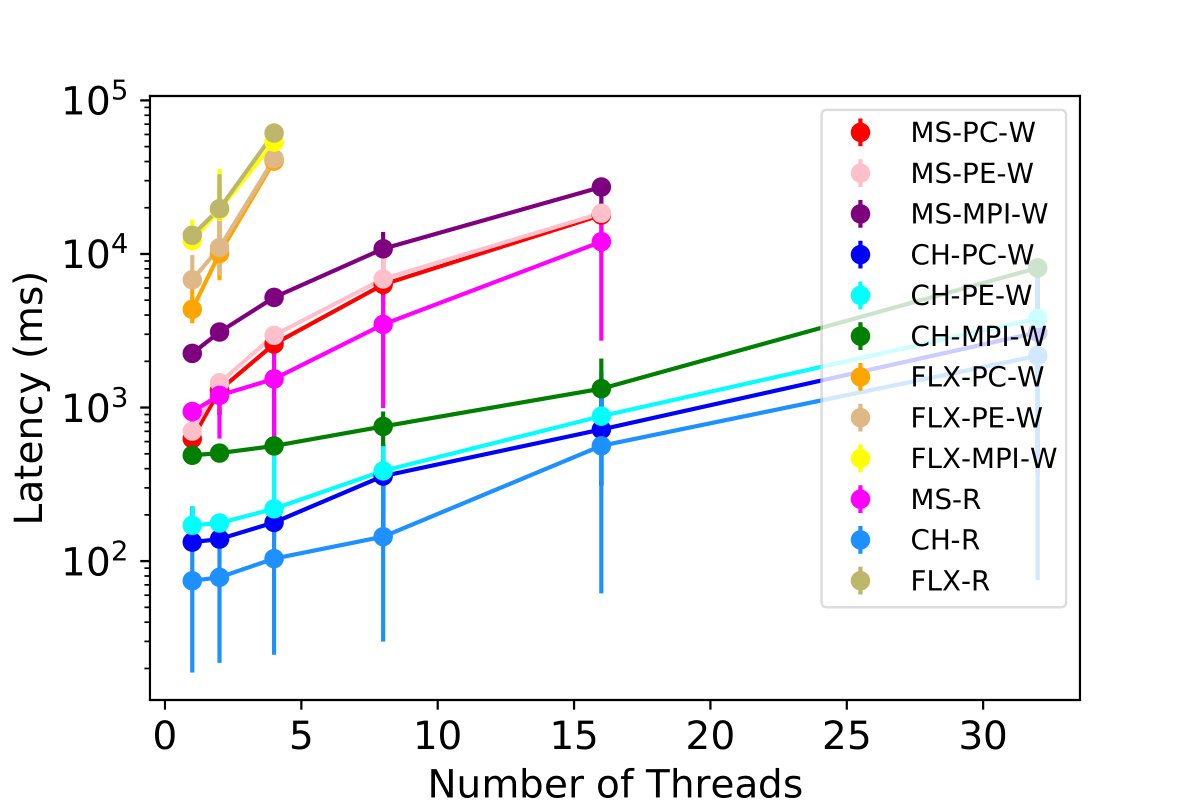
Scalling efficency of latency based on tables being written to when each thread is handeling 50k rows
Accessing Single Table
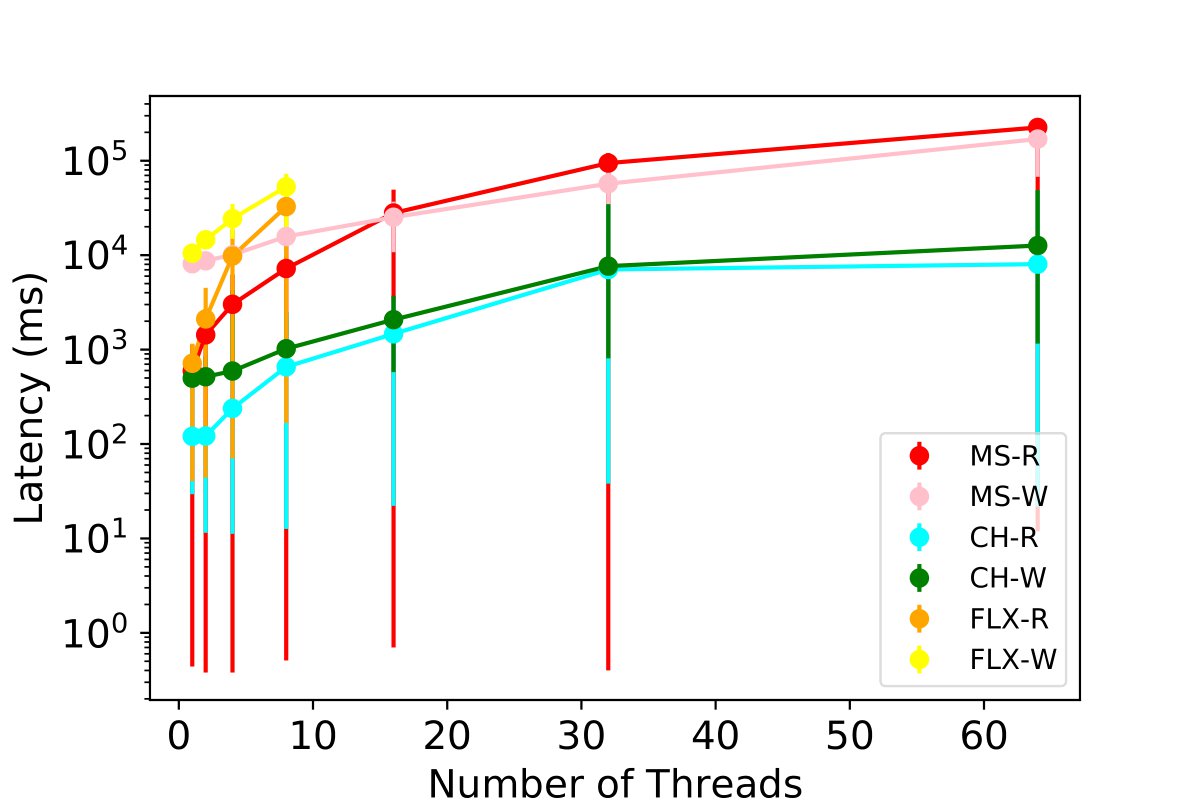
Accessing Two Tables
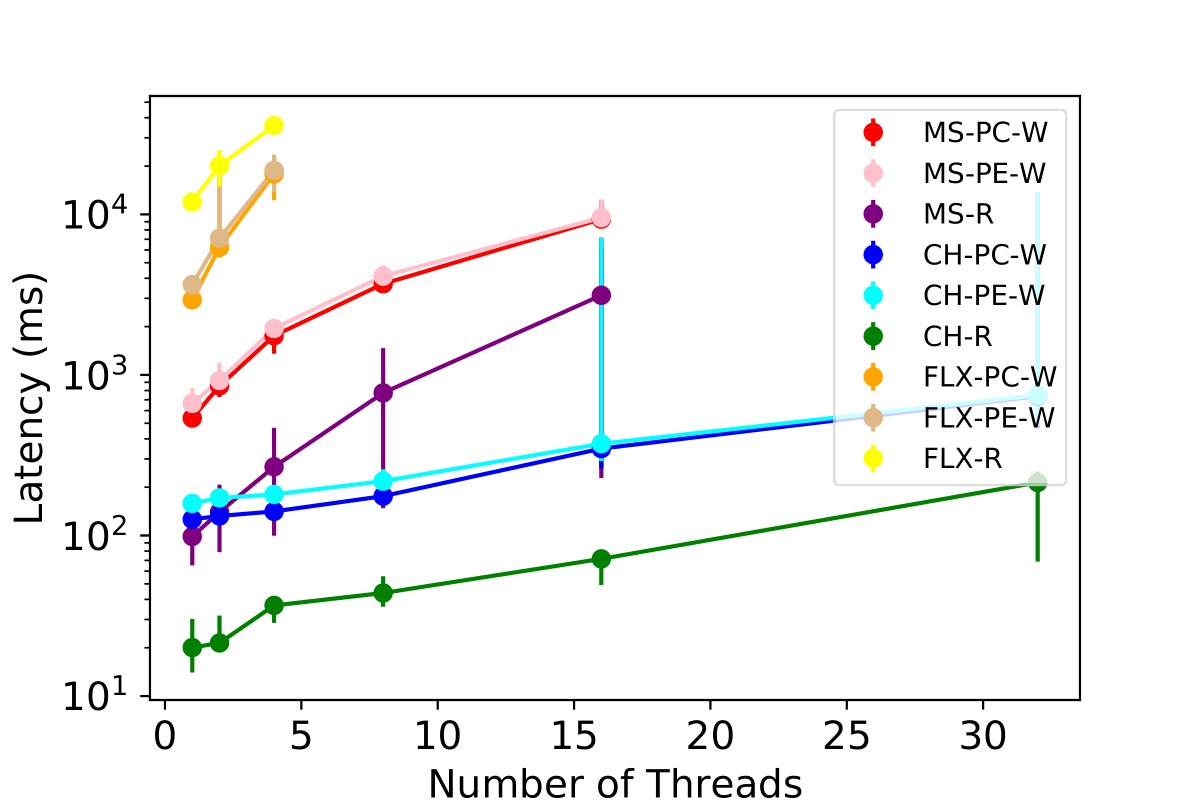
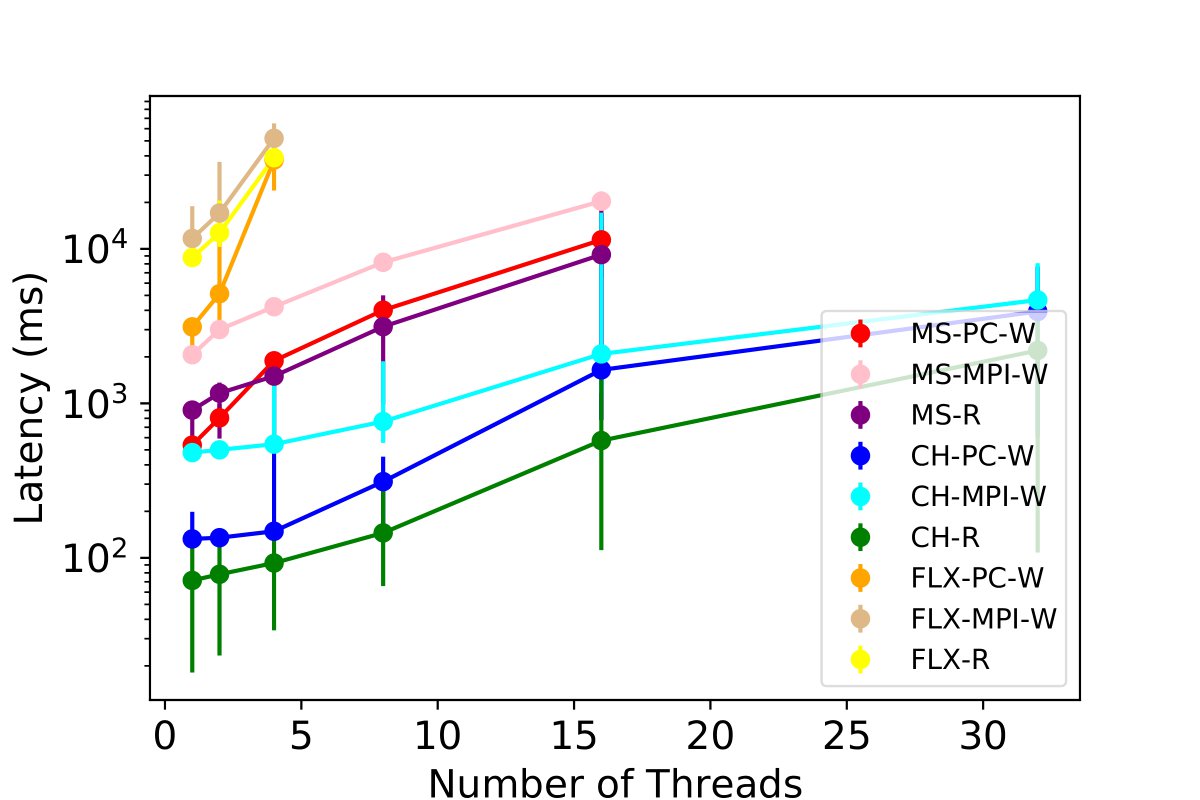
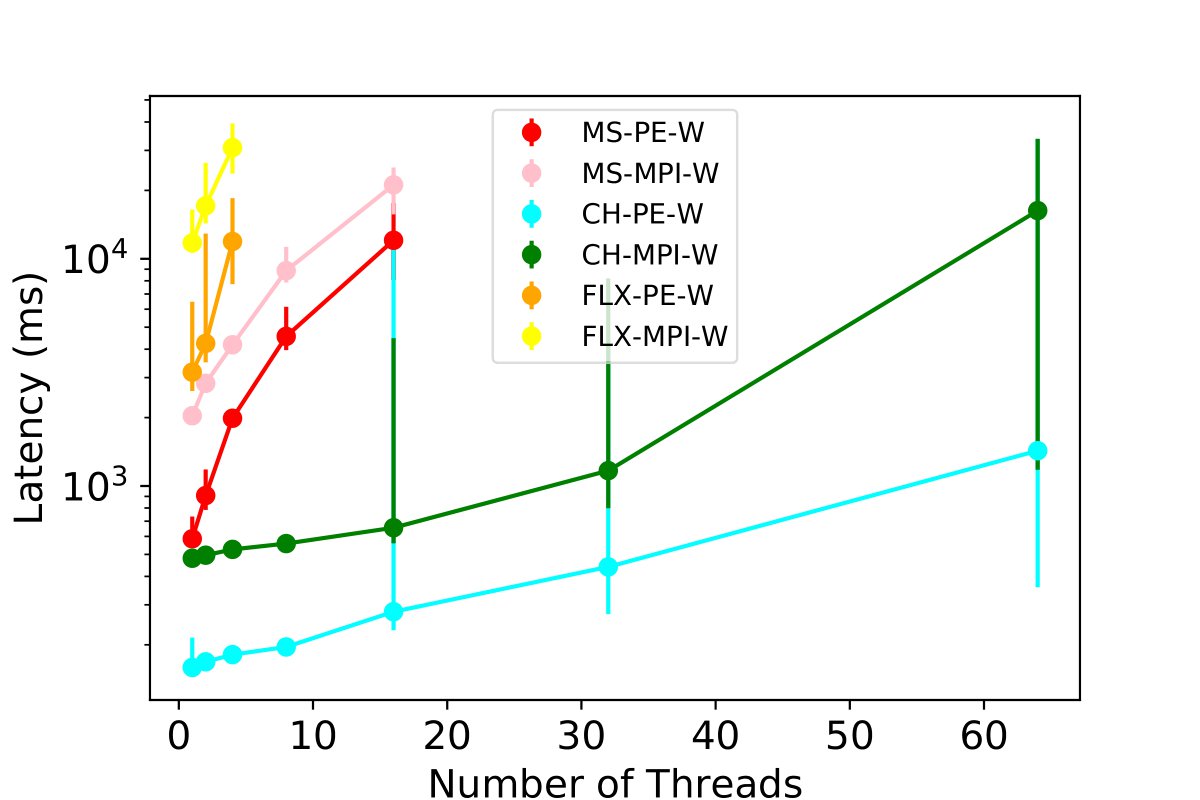
Accessing Three Most Used Tables
In-production Performance Evaluation of INAM with Different Database Options
We have incorporated and deployed three database options into INAM, utilizing it on the OSC cluster to conduct high-fidelity profiling stress tests and validate our findings. The tests used a 1-second interval for profiling the InfiniBand network, a 5-second interval for profiling both MPI and jobs metrics with an 80% cluster load, and a background deletion of data older than 1 hour. Consequently, this evaluation demonstrates a real-world deployment of INAM with varying database options. We also performed detailed timing measurements for each component.
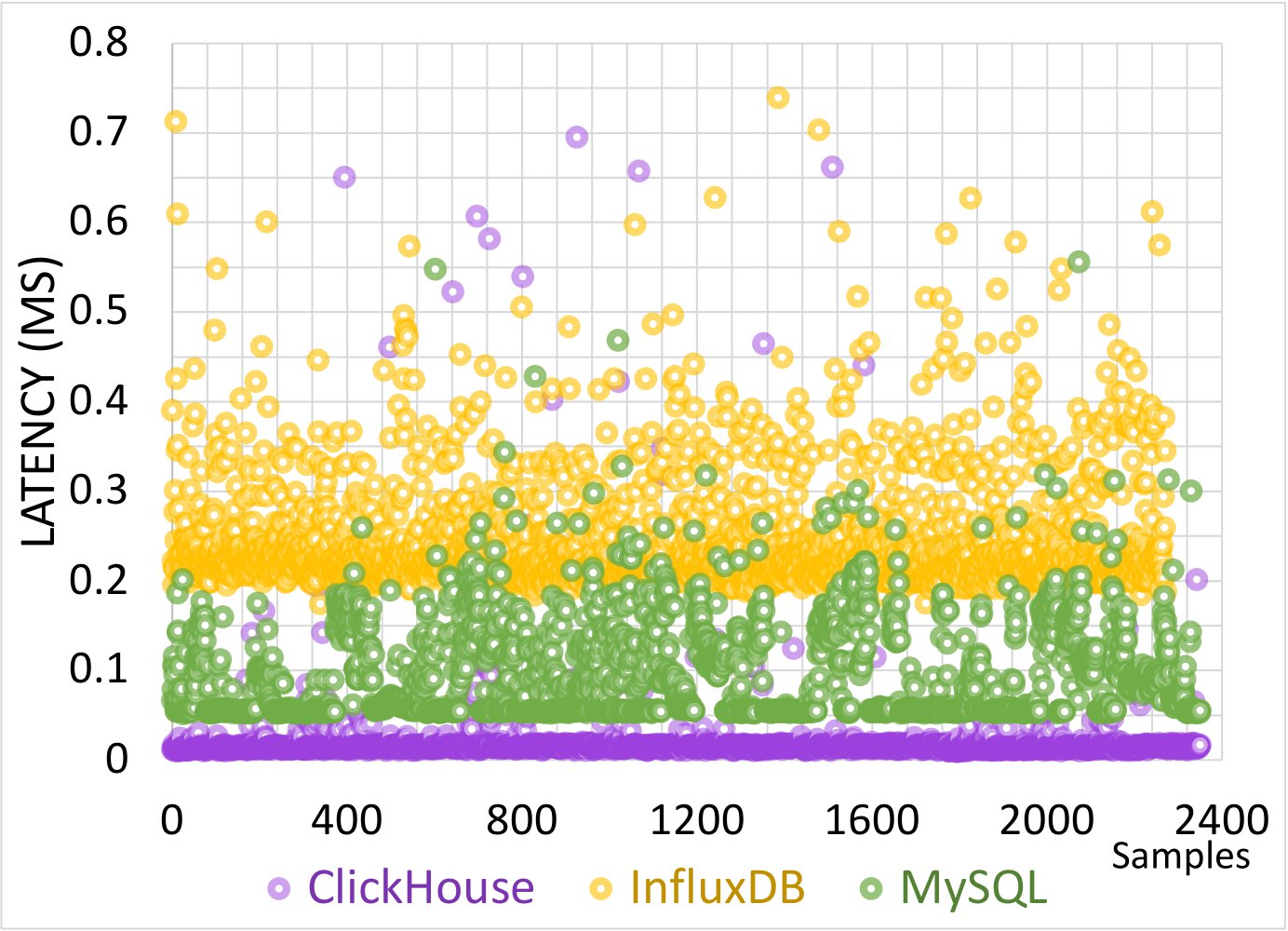
This figure presents a comparison of the total latency involved in gathering and storing PC and PE data from the network across various databases. Each point reflects the total latency across all threads for insertion and collection. Eight threads were employed for data insertion, and this experiment was repeated for 2,400 samples. Notably, ClickHouse consistently exhibited superior performance stability compared to the other databases.
