Job Startup
Overview
- Near-constant MPI and OpenSHMEM initialization time at any process count
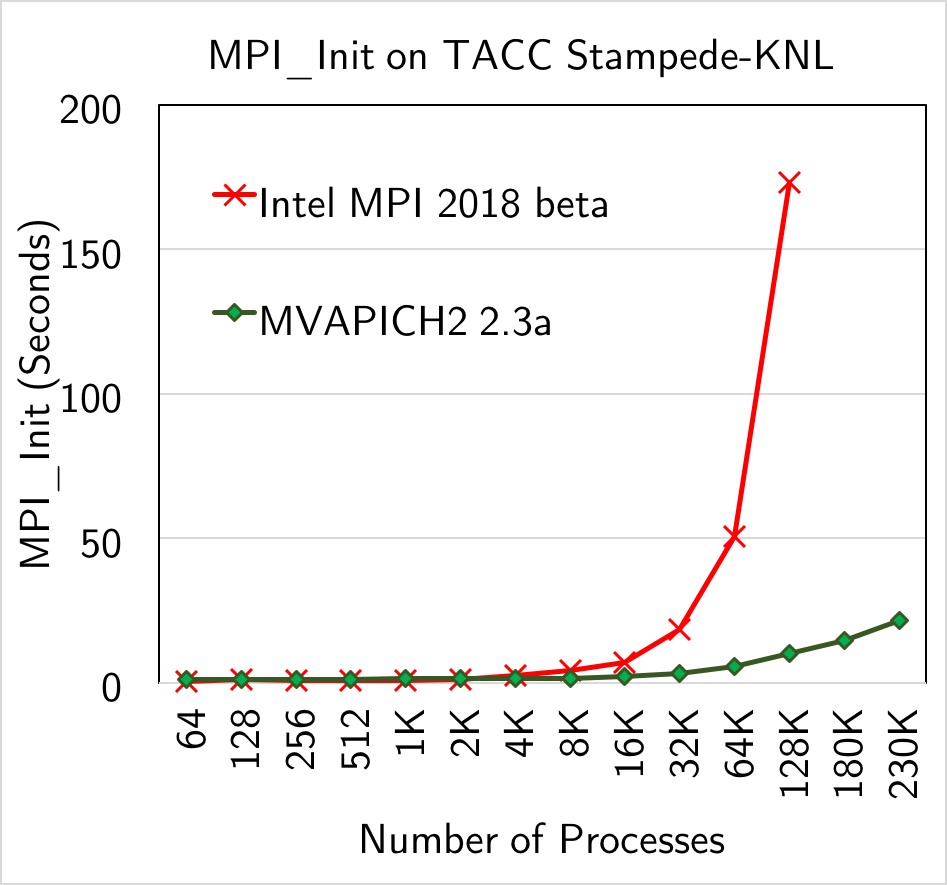
- MPI_Init completed under 22 seconds with 229,376 processes on 3,584 KNL nodes. (Courtesy: Jerome Vienne @ TACC)
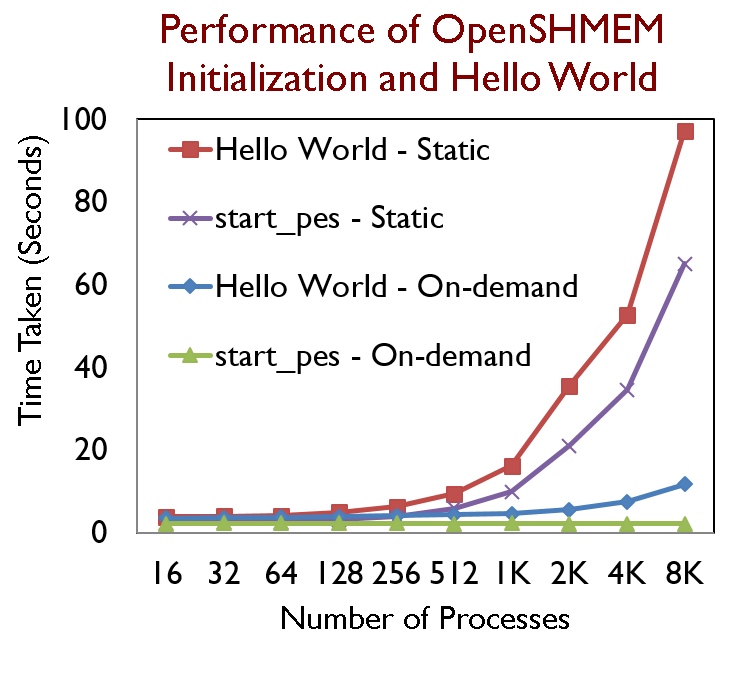
- 10x and 30x improvement in startup time of MPI and OpenSHMEM respectively at 16,384 processes
- Reduce memory consumption by O(ppn)
- 1GB Memory saved per node @ 1M processes and 16 processes per node
Best Practices for Enhancing Job Startup Performance with MVAPICH2
Launcher Agnostic Optimizations
- Configuration options
- ./configure --disable-rdma-cm
- Disable RDMA_CM
- ./configure --disable-rdma-cm
- Runtime parameters
- MV2_HOMOGENEOUS_CLUSTER
- Set to 1 for homogeneous clusters
- MV2_ON_DEMAND_THRESHOLD
- Job size after which on-demand connection management should be enabled
- Set to 1 so that jobs of all sizes use on-demand connection management
- MV2_ON_DEMAND_UD_INFO_EXCHANGE
- Set to 1 to enable on-demand creation of UD address handles when MVAPICH2 is run in hybrid mode
- MV2_HOMOGENEOUS_CLUSTER
Optimizations for SLURM
- Use PMI2
- ./configure --with-pm=slurm --with-pmi=pmi2
- srun --mpi=pmi2 ./a.out
- Use PMI Extensions
- Patch for SLURM 15 and 16 available here
- PMI Extensions are automatically detected and used by MVAPICH2 2.2rc1 and higher
Optimizations for mpirun_rsh
- MV2_MT_DEGREE
- Degree of the hierarchical tree used by mpirun_rsh
- MV2_FASTSSH_THRESHOLD
- Number of nodes beyond which hierarchical-ssh scheme is used
- MV2_NPROCS_THRESHOLD
- Number of nodes beyond which file-based communication is used for hierarchical-ssh during start up
Hardware Specifications
| CPU Model | CPU Core Info | Memory | Network Interconnect | Switch | OS | Intel OPA |
|---|---|---|---|---|---|---|
| Intel Xeon Phi 7250 | 68 cores @ 1.4Ghz | 96GB (DDR4) | Intel Omni-Path (100Gbps) | Intel Omni-Path Switch (100Gbps) | RHEL 7 | N/A |
Performance on Intel Knights Landing + Omni-Path
- Enhanced job startup performance on KNL+Omni-Path systems with new designs in MVAPICH2-2.3a
- MPI_Init completed under 22 seconds with 229,376 processes on 3,584 KNL nodes. (Courtesy: Jerome Vienne @ TACC)
- 8.8 times faster than Intel MPI with 128K processes
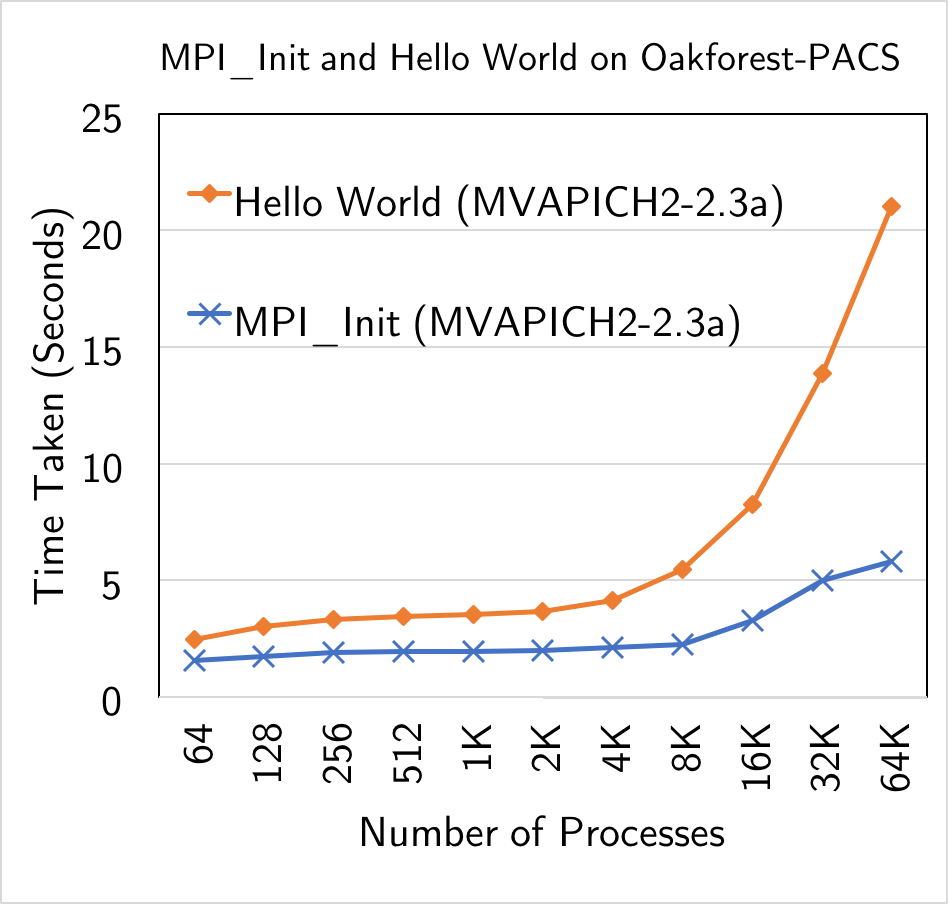
- MPI_Init in 5.8s and Hello World in 21s with 64K processes on Oakforest-PACS
- Tests run with 64 processes per KNL node
Hardware Specifications
| CPU Model | CPU Core Info | Memory | IB Card | IB Switch | OS | OFED |
|---|---|---|---|---|---|---|
| Intel E5-2680 | 2x8 @ 2.7Ghz | 32GB | Mellanox ConnectX-3 (56Gbps) | Mellanox FDR IB Switch (56Gbps) | CentOS 6.7 | OFED 1.5.4.1 |
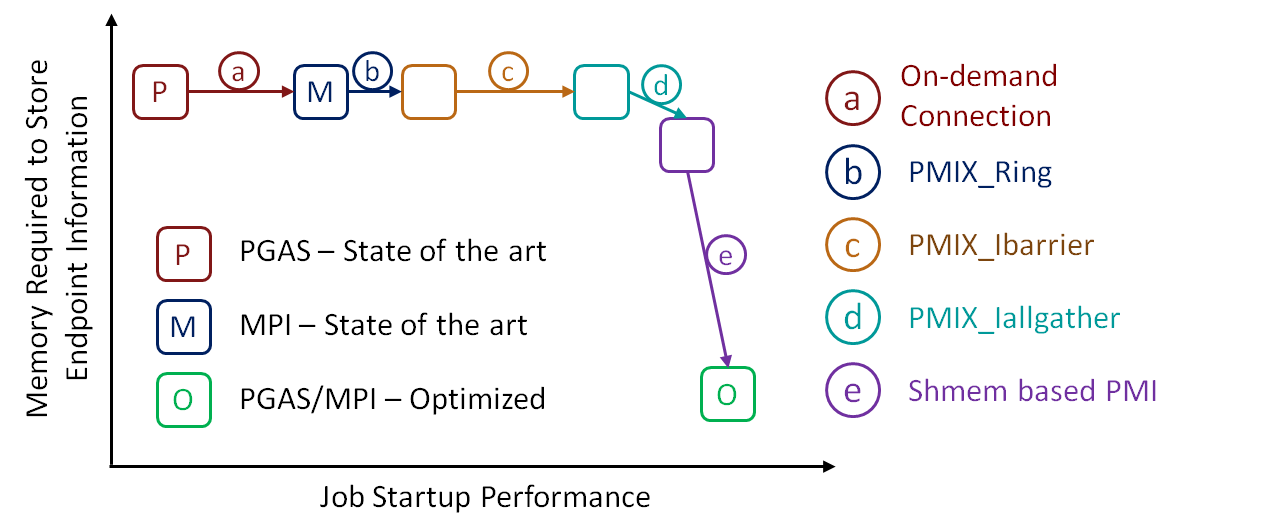
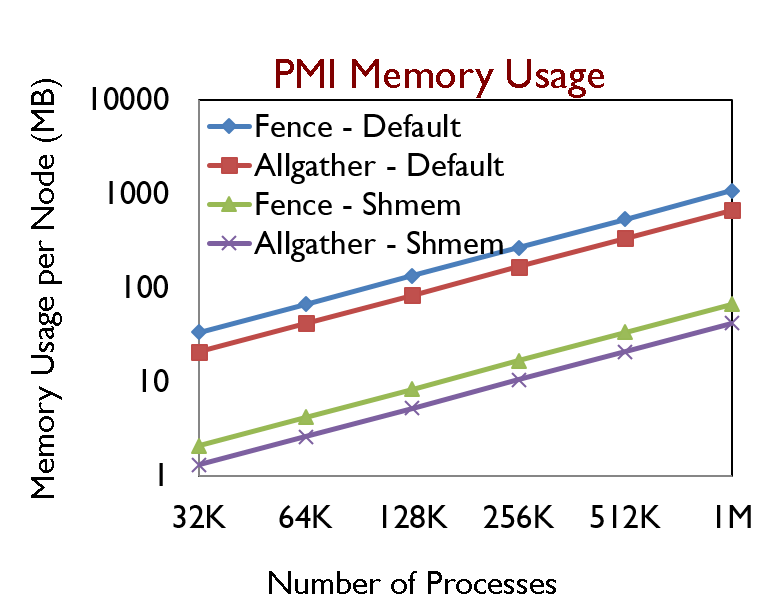
Shared Memory based PMI
- Introduced in MVAPICH2-2.2rc1, available with srun slurm patch
- PMI Get takes 0.25 ms with 32 ppn
- 1,000 times reduction in PMI Get latency compared to default socket based protocol
- Memory footprint reduced by O(Processes Per Node) ≈ 1GB @ 1M processes, 16 ppn
- Backward compatible, negligible overhead
Non-blocking PMI
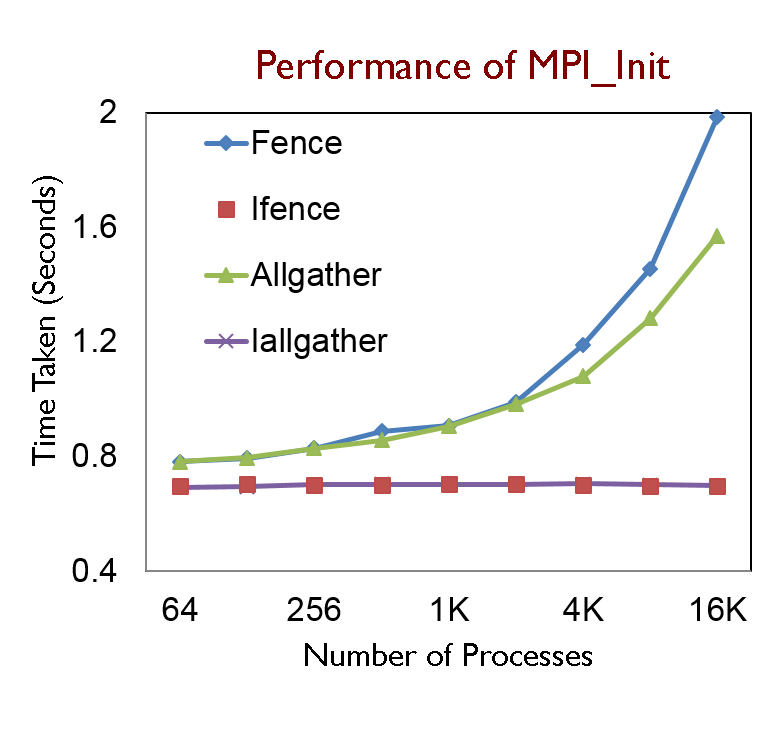
- Introduced in MVAPICH2-2.2b, enabled with mpirun_rsh by default for srun with slurm patch
- Near-constant MPI_Init at any scale
- MPI_Init with Iallgather performs 288% better than the default based on Fence
- Blocking Allgather is 38% faster than blocking Fence
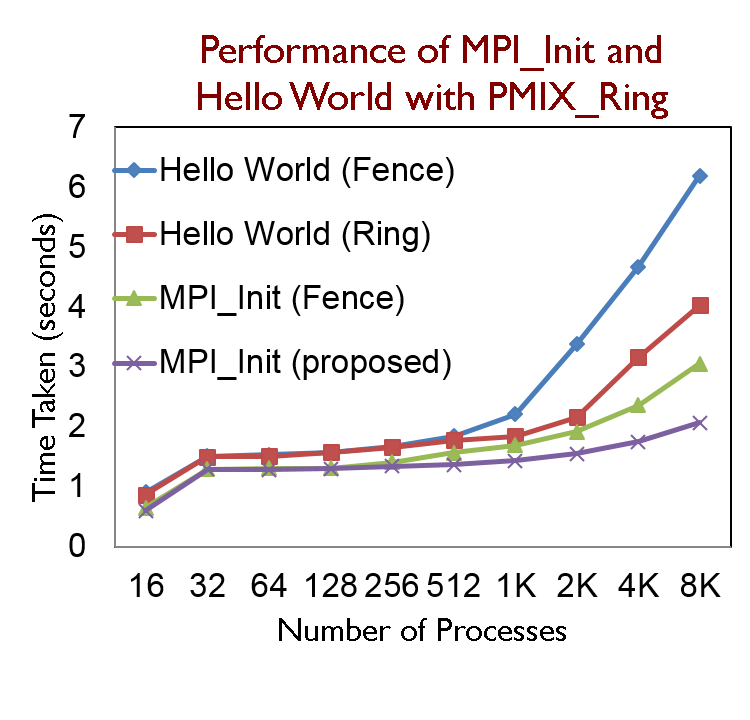
PMI Ring Extension
- Superseded by non-blocking PMI
- MPI_Init based on PMIX_Ring performs 34% better compared to the default PMI2_KVS_Fence
- Hello World runs 33% faster with 8K processes
- Up to 20% improvement in total execution time of NAS parallel benchmarks
On-demand Connection
- Introduced in MVAPICH2-X 2.1rc1, click here for more information
- 29.6 times faster initialization time
- Hello world performs 8.31 times better
- Execution time of NAS benchmarks improved by up to 35% with 256 processes and class B data