

MVAPICH2 (MPI-3.1 over OpenFabrics-IB, Omni-Path, OpenFabrics-iWARP, PSM, and TCP/IP)
This is an MPI-3.1 implementation. The latest release is MVAPICH2 2.3.7 (includes MPICH-3.2.1). It is available under BSD licensing.
The current release supports the following ten underlying transport interfaces:- OFA-IB-CH3: This interface supports all InfiniBand compliant devices based on the OpenFabrics Gen2 layer. This interface has the most features and is most widely used. For example, this interface can be used over all Mellanox InfiniBand adapters, IBM eHCA adapters and Qlogic adapters.
- OFA-IB-Nemesis (Deprecated): This interface supports all InfiniBand compliant devices based on the OpenFabrics libibverbs layer with the emerging Nemesis channel of the MPICH2 stack. This interface can be used by all Mellanox InfiniBand adapters.
- OFA-iWARP-CH3: This interface supports all iWARP compliant devices supported by OpenFabrics. For example, this layer supports Chelsio T3 adapters with the native iWARP mode.
- OFA-RoCE-CH3: This interface supports the emerging RoCE (RDMA over Convergence Ethernet) interface for Mellanox ConnectX-EN adapters with 10/40GigE switches. It provides support for RoCE v1 and v2.
- TrueScale(PSM-CH3): This interface provides native support for TrueScale adapters from Intel over PSM interface. It provides high-performance point-to-point communication for both one-sided and two-sided operations.
- Omni-Path(PSM2-CH3): This interface provides native support for Omni-Path adapters from Intel over PSM2 interface. It provides high-performance point-to-point communication for both one-sided and two-sided operations.
- Shared-Memory-CH3: This interface provides native shared memory support on multi-core platforms where communication is required only within a node. Such as SMP-only systems, laptops, etc.
- TCP/IP-CH3: The standard TCP/IP interface (provided by MPICH2) to work with a range of network adapters supporting TCP/IP interface. This interface can be used with IPoIB (TCP/IP over InfiniBand network) support of InfiniBand also. However, it will not deliver good performance/ scalability as compared to the other interfaces.
- TCP/IP-Nemesis: The standard TCP/IP interface (provided by MPICH2 Nemesis channel) to work with a range of network adapters supporting TCP/IP interface. This interface can be used with IPoIB (TCP/IP over InfiniBand network) support of InfiniBand also. However, it will not deliver good performance/ scalability as compared to the other interfaces.
- Shared-Memory-Nemesis: This interface provides native shared memory support on multi-core platforms where communication is required only within a node. Such as SMP-only systems, laptops, etc.
MVAPICH2 2.3.7 provides many features including MPI-3.1 standard compliance, single copy intra-node communication using Linux supported CMA (Cross Memory Attach), Checkpoint/Restart using LLNL's Scalable Checkpoint/Restart Library (SCR), support for PMIx protocol for SLURM and JSM process managers, high-performance and scalable InfiniBand hardware multicast-based collectives, enhanced shared-memory-aware and intra-node Zero-Copy collectives (using LiMIC), high-performance communication support for NVIDIA GPU with IPC, collective and non-contiguous datatype support, integrated hybrid UD-RC/XRC design, support for UD only mode, nemesis-based interface, shared memory interface, scalable and robust daemon-less job startup (mpirun-rsh), flexible process manager support (mpirun-rsh and mpiexec.hydra), full autoconf-based configuration, portable hardware locality (hwloc) with flexible CPU granularity policies (core, socket and numanode) and binding policies (bunch and scatter) with SMT support, flexible rail binding with processes for multirail configurations, message coalescing, dynamic process migration, fast process-level fault-tolerance with checkpoint-restart, fast job-pause-migration-resume framework for pro-active fault-tolerance, suspend/resume, network-level fault-tolerance with Automatic Path Migration (APM), RDMA CM support, iWARP support, optimized collectives, on-demand connection management, multi-pathing, RDMA Read-based and RDMA-write-based designs, polling and blocking-based communication progress, multi-core optimized and scalable shared memory support, LiMIC2-based kernel-level shared memory support for both two-sided and one-sided operations, shared memory backed Windows for one-Sided communication, HugePage support, and memory hook with ptmalloc2 library support. The ADI-3-level design of MVAPICH2 2.3.7 supports many features including: MPI-3.1 functionalities (one-sided, dynamic process management, collectives and datatype), multi-threading and all MPI-1 functionalities. It also supports a wide range of platforms, architectures, OS, compilers, InfiniBand adapters (Mellanox and Intel), Omni-Path adapters from Intel, iWARP adapters (including the new Chelsio T5 adapter) and RoCE adapters. A complete set of features and supported platforms can be found here..
The complete MVAPICH2 2.3.7 package is available through public anonymous MVAPICH SVN.
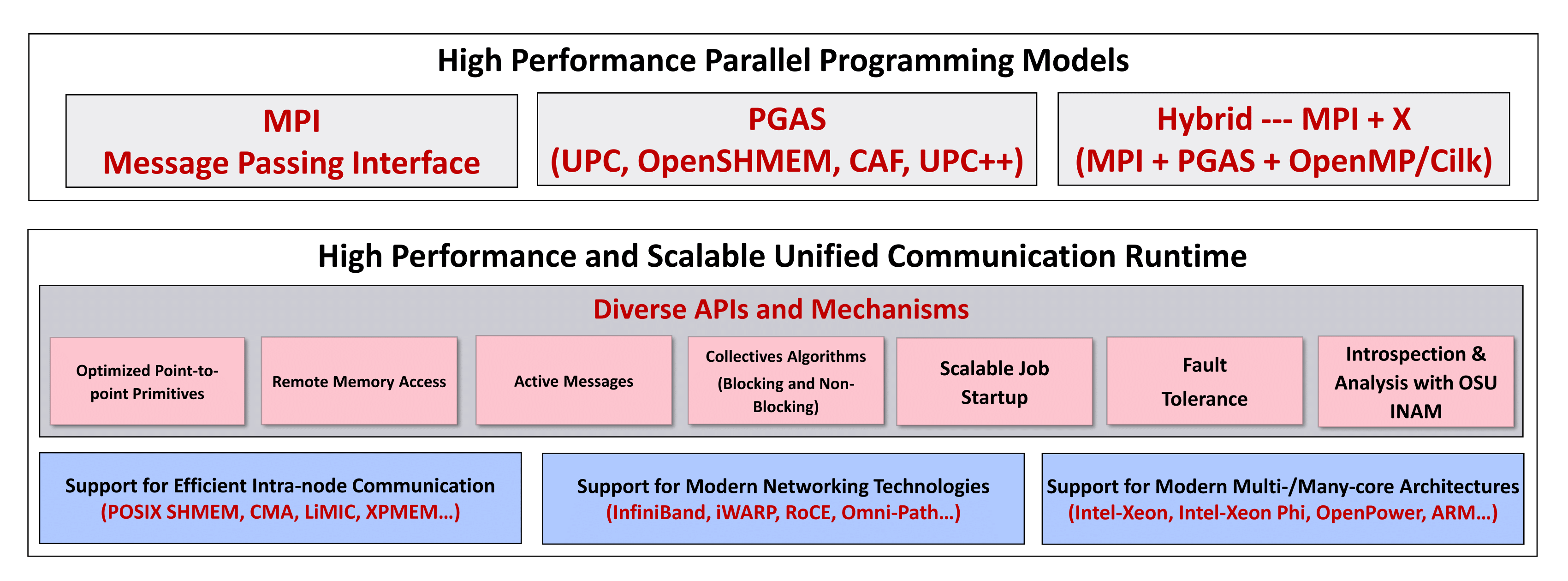
MVAPICH2-X (Advanced MPI and Unified MPI+PGAS Communication Runtime for Exascale Systems)
Message Passing Interface (MPI) has been the most popular programming model for developing parallel scientific applications. Partitioned Global Address Space (PGAS) programming models are an attractive alternative for designing applications with irregular communication patterns. They improve programmability by providing a shared memory abstraction while exposing locality control required for performance. It is widely believed that hybrid programming model (MPI+X, where X is a PGAS model) is optimal for many scientific computing problems, especially for exascale computing.
MVAPICH2-X provides support for advanced MPI features (Dynamically Connected (DC) transport protocol, User Mode Memory Registration, On-Demand Paging (ODP), Support Data Partitioning-based Multi-Leader Design (DPML) for MPI collectives, Support Contention Aware Kernel-Assisted MPI collectives, and Non-blocking Collectives with Core-Direct), OSU INAM and hybrid MPI+PGAS (UPC, OpenSHMEM, CAF, and UPC++) programming models with unified communication runtime for emerging exascale systems. This library also provides flexibility for users to write applications using the following programming models with a unified communication runtime: MPI, MPI+OpenMP, pure UPC, pure OpenSHMEM, pure UPC++, and pure CAF programs as well as hybrid MPI(+OpenMP) + PGAS (UPC, OpenSHMEM, CAF, and UPC++) programs. It enables developers to port parts of large MPI applications that are suited for PGAS programming model. This minimizes the development overheads that have been a huge deterrent in porting MPI applications to use PGAS models. The unified runtime also delivers superior performance compared to using separate MPI and PGAS libraries by optimizing use of network and memory resources. The DCT support is also available for the PGAS models.
MVAPICH2-X supports Unified Parallel C (UPC), UPC++, OpenSHMEM and Coarray Fortran (CAF) as PGAS models. It can be used to run pure MPI, MPI+OpenMP, pure UPC, pure UPC++, pure OpenSHMEM, pure CAF as well as hybrid MPI(+OpenMP) + PGAS applications. MVAPICH2-X derives from the popular MVAPICH2 library and inherits many of its features for performance and scalability of MPI communication. It takes advantage of the RDMA features offered by the InfiniBand interconnect to support UPC/UPC++/OpenSHMEM/CAF data transfer and atomic operations. It also provides a high-performance shared memory channel for multi-core InfiniBand clusters.
The MPI implementation of MVAPICH2-X is based on MVAPICH2, which supports all MPI-3 features. The UPC implementation is UPC Language Specification v1.2 standard compliant and is based on Berkeley UPC v2.20.2. The UPC++ implementation is based on Berkeley UPC++ v0.1. OpenSHMEM implementation is OpenSHMEM v1.3 standard compliant and is based on OpenSHMEM Reference Implementation v1.3. CAF implementation is Fortran 2008 standard compliant with support for extensions proposed by the 2015 specification working group. It is based on the UH CAF 3.0.39 Implementation. The current release supports communication using InfiniBand Transport (inter-node) and Shared Memory (intra-node). The overall architecture of MVAPICH2-X is shown in the figure below.
MVAPICH2-GDR (MVAPICH2 with GPUDirect RDMA)
MVAPICH2-GDR, based on the standard MVAPICH2 software stack, incorporates designs that take advantage of the new GPUDirect RDMA technology for inter-node data movement on NVIDIA GPUs clusters with Mellanox InfiniBand interconnect. GPUDirect RDMA completely by-passes the host memory, providing low-latency and completely offloaded communication between NVIDIA GPUs on a cluster. MVAPICH2-GDR reaps the benefits of this new fast communication path while offering hybrid designs that help work around peer-to-peer bandwidth bottlenecks seen on modern node architectures. It provides significantly improved performance for small and medium messages while achieving close to peak network bandwidth for large messages.
MVAPICH2-GDR also inherits all the features for communication on NVIDIA GPU clusters that are available in the MVAPICH2 software stack. A complete list of these features can be found here.
MVAPICH2-J (Java bindings for MVAPICH2)
MVAPICH2-J 2.3.7 is a Java bindings to the MVAPICH2 family of libraries. The MVAPICH2-J software currently provides support for communicating data from basic Java datatypes as well as direct ByteBuffers from the Java New I/O (NIO) package. The software supports blocking/non-blocking point-to-point, blocking collective, blocking strided collective functions and some Dynamic Process Management (DPM) functionality. The library utilizes the Java Native Interface (JNI) to maintain a minimal Java layer that allows for easier development and maintenance.
Since MVAPICH2-J is a Java binding of MVAPICH2 it also inherits all the features for communication for IB, RoCE (v1 and v2) and iWARP available in the MVAPICH2 software stack. A complete list of these features can be found here.
For more information on the usage of MVAPICH2-J, please refer to the Userguide
MVAPICH2-MIC (MVAPICH2 with Xeon Phi (MIC) Support)
MVAPICH2-MIC, based on the standard MVAPICH2 software stack, incorporates hybrid designs that use Shared memory, SCIF and IB channels to optimize intra-node and inter-node data movement on Xeon Phi clusters.
MVAPICH2-MIC supports the three modes of MIC-based system usage: Offload, Native and Symmetric. In Offload mode, MPI processes are executed on the host processors. The Xeon Phi works as an accelerator to offload computation onto. This mode is similar to most GPGPU clusters where GPUs are only used to accelerate computation. The Coprocessor-only (Native) mode means to run all MPI processes only on the MIC architecture and the Hosts are not involved in the execution. In the Symmetric mode of operation, MPI processes are uniformly spawned over both the host and the coprocessor architectures. The developer has to explicitly manage parallelism across the two different architectures.
With the two last modes, in order to optimize the intra-MIC communication, MVAPICH2-MIC uses hybrid schemes that mix shared memory and SCIF channels. Similar hybrid designs with SCIF and IB are used to efficiently support Intra-node Host-MIC communications. To overcome the Bandwidth limitation of the current chipsets (SandyBridge and Ivybridge), MVAPICH2-MIC, employs 3 different proxy-based designs : active 1-hop, active 2-hops and passive that efficiently and transparently reroute the communication through the host. The proxy designs use a hybrid scheme which efficiently pipelines the communication utilizing SCIF and IB channels. For more information on the usage and tuning of MVAPICH2-MIC please refer to the README.
MVAPICH2-MIC also inherits all the features for communication on HPC Clusters available in the MVAPICH2 software stack. A complete list of these features can be found here
MVAPICH2-Virt (MVAPICH2 with Virtualization Support)
MVAPICH2-Virt, based on the standard MVAPICH2 software stack, incorporates designs that take advantage of the new features and mechanisms of high-performance networking technologies with SR-IOV as well as other virtualization technologies such as Inter-VM Shared Memory (IVSHMEM), IPC enabled Inter-Container Shared Memory (IPC-SHM), Cross Memory Attach (CMA), and OpenStack. For SR-IOV-enabled InfiniBand virtual machine environments and InfiniBand based container environments, MVAPICH2-Virt has very little overhead compared to MVAPICH2 running over InfiniBand in native mode. MVAPICH2-Virt can deliver the best performance and scalability to MPI applications running inside both virtual machines and containers over SR-IOV enabled InfiniBand clusters.
In MVAPICH2-Virt, for VMs, Intra-Node-Intra-VM MPI communication can use Cross Memory Attach (CMA) channel, Intra-Node-Inter-VM MPI communication can go through IVSHMEM-based channel, while Inter-Node-Inter-VM MPI communication can leverage SR-IOV-based channel. For containers, all Intra-Node MPI communication can go through either IPC-SHM enabled channel or CMA channel, no matter they are in the same container or different ones. Inter-Node-Inter-Container MPI communication will leverage the InfiniBand channel. For processes which are distributed in different VMs/containers, MVAPICH2-Virt can transparently detect the process locality to dynamically select the optimized channel for high-performance data communication. For more information on the usage and tuning of MVAPICH2-Virt, please refer to the Userguide.
MVAPICH2-Virt also inherits all the features for communication on HPC Clusters that are available in the MVAPICH2 software stack. A complete list of these features can be found here.
MVAPICH2-EA (MVAPICH2 with Energy Aware MPI)
MVAPICH2-EA 2.1 (Energy-Aware) binary release is based on MVAPICH2 2.1 and incorporates designs and algorithms that optimize the performance-energy trade-off. In other words, MVAPICH2-EA, is a white-box approach that reduces energy consumption with minimal or no degradation in performance. Further, the intelligence inside the MVAPICH2-EA achieves energy saving while allowing for user-permitted degradation in performance using a Tolerance percentage parameter.
MVAPICH2-EA also inherits all the features for communication fro IB, RoCE (v1 and v2) and iWARP available in the MVAPICH2 software stack. A complete list of these features can be found here.
Furthermore, as part of the MVAPICH2-EA package, we provide an OSU Energy Monitoring Tool (OEMT), that allows the users to measure the energy consumption of their MPI application. For more details on the OEMT tool, please refer to the OEMT page
For more information on the usage and tuning of MVAPICH2-EA and OEMT, please refer to the Userguide

