

1. Overview
MVAPICH2-GDR 2.3.7 binary release is based on MVAPICH2 2.3.7 and incorporates designs that take advantage of GPUDirect RDMA technology enabling direct P2P communication between NVIDIA GPUs and Mellanox InfiniBand adapters. MVAPICH2-GDR 2.3.7 also adds support for AMD GPUs via Radeon Open Compute (ROCm) software stack and exploits ROCm RDMA technology for direct communication between AMD GPUs and Mellanox InfiniBand adapters. MVAPICH2-GDR 2.3.7 offers significant improvements in latency and bandwidth for GPU-buffer based intranode and internode MPI Communication involving small and medium message sizes. For more information on the GPUDirect RDMA technology, refer to https://www.mellanox.com/products/GPUDirect-RDMA.
MVAPICH2-GDR 2.3.7 provides an efficient support for Non-Blocking Collectives (NBC) from GPU buffers to achieve maximal overlap. It uses novel designs that combine GPUDirect RDMA and Core-Direct technologies. Further MVAPICH2-GDR 2.3.7 also provides support for CUDA Managed memory features and optimizes large message collectives targeting Deep Learning frameworks.
Note that this release is for GPU-Cluster with GPUDirect RDMA support, if your cluster does not have this support please use the default MVAPICH2 library. For more details please refer to http://mvapich.cse.ohio-state.edu/.
2. Supported Platforms
-
Intel and other x86 Systems
-
OpenPOWER 8 and 9 Systems
3. System Requirements
MVAPICH2-GDR 2.3.7 binary release requires the following software to be installed on your system:
3.1. NVIDIA GPUs
List of Mellanox InfiniBand adapters and NVIDIA GPU devices which support GPUDirect RDMA can be found here.
4. Strongly Recommended System Features
MVAPICH2-GDR 2.3.7 boosts the performance by taking advantage of the new GDRCOPY module from NVIDIA. In order to take advantage of this feature, please download and install this module from:
(https://github.com/NVIDIA/gdrcopy)For GDRCopy v2.x, please use MVAPICH2-GDR v2.3.3 or newer versions.
After installing this module you need to add this path to your LD_LIBRARY_PATH or use MV2_GPUDIRECT_GDRCOPY_LIB to pass this path to the MPI library at runtime. For more details please refer to section (GDRCOPY USAGE AND TUNING) of this README. Note that even if this module is not available, MVAPICH2-GDR 2.3.7 will deliver very good performance by taking advantage of the Loopback feature. For more details refer to section (LOOPBACK FEATURE) of this README.
For ROCm version of MVAPICH2-GDR, you do not have to specify the path to GDRCOPY library. The rest of the tuning parameters for GDRCOPY are still applicable.
5. Installing MVAPICH2-GDR library
To install the MVAPICH2-GDR library you simply need to select the correct library (MOFED version, Compiler version, etc.) for your system and install the RPM using your favorite RPM tool. Please use the downloads page (http://mvapich.cse.ohio-state.edu/downloads/) to find the appropriate RPM link and follow the instructions below.
$ wget http://mvapich.cse.ohio-state.edu/download/mvapich/gdr/2.3.7/<mv2-gdr-rpm-name>.rpm $ rpm -Uvh --nodeps <mv2-gdr-rpm-name>.rpm
The RPMs contained in our libraries are relocatable and can be installed using a prefix other than the default of ./opt/mvapich2/ used by the library in the previous example.
$ rpm --prefix /custom/install/prefix -Uvh --nodeps <mv2-gdr-rpm-name>.rpm
If you do not have root permission you can use rpm2cpio to extract the library.
$ rpm2cpio <mv2-gdr-rpm-name>.rpm | cpio -id
When using the rpm2cpio method, you will need to update the MPI compiler scripts, such as mpicc, in order to point to the correct path of where you place the library.
|
Tip
|
If you are using a Debian based system such as Ubuntu you can convert the rpm to a deb using a tool such as alien or follow the rpm2cpio instructions above. |
6. Installing MVAPICH2-GDR using Spack
MVAPICH2-GDR can be installed using Spack without building it from source. See the Spack userguide for details: https://mvapich.cse.ohio-state.edu/userguide/userguide_spack/
7. Running applications
Here are some examples running applications with the MVAPICH2-GDR software.
7.1. Example running OSU Micro Benchmark for NVIDIA GPUs
To run point-to-point and collective benchmarks for measuring internode latency between GPUs when enabling GPUDirect RDMA-based designs in MVAPICH2-GDR 2.3.7
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_GPUDIRECT_GDRCOPY_LIB=/path/to/GDRCOPY/install/lib64/libgdrapi.so 3: $ export MV2_USE_CUDA=1 4: 5: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 6: $MV2_PATH/libexec/osu-micro-benchmarks/get_local_rank \ 7: $MV2_PATH/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_latency D D 8: 9: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 10: $MV2_PATH/libexec/osu-micro-benchmarks/get_local_rank \ 11: $MV2_PATH/libexec/osu-microbenchmarks/mpi/collective/osu_allreduce -d cuda
7.2. Example running OSU Micro Benchmark for AMD GPUs
To run point-to-point and collective tests running on AMD GPUs using ROCm-aware designs in MVAPICH2-GDR 2.3.7
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_USE_ROCM=1 3: 4: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 5: $MV2_PATH/libexec/osu-micro-benchmarks/get_local_rank \ 6: $MV2_PATH/libexec/osu-micro-benchmarks/mpi/pt2pt/osu_latency D D 7: 8: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 9: $MV2_PATH/libexec/osu-micro-benchmarks/get_local_rank \ 10: $MV2_PATH/libexec/osu-microbenchmarks/mpi/collective/osu_allreduce -d rocm
Note: When using Spack installation, if you did not use spack load command, you may need to prepend MVAPICH2-GDR library to LD_LIBRARY_PATH like this:
$ export LD_LIBRARY_PATH=$HOME/spack/opt/spack/linux-centos7-x86_64/gcc-<ver>/mvapich2-gdr-<ver>-<hash>/lib/:$LD_LIBRARY_PATH7.3. Example running Deep Learning Frameworks with Horovod and MVAPICH2-GDR
MVAPICH2-GDR supports TensorFlow/PyTorch/MXNet with Horovod/MPI design but a special flag is needed to run the jobs properly. Please use the MV2_SUPPORT_DL=1 or MV2_SUPPORT_TENSOR_FLOW=1 runtime variable but do not use the LD_PRELOAD option. The variable MV2_SUPPORT_TENSOR_FLOW will be deprecated in the future.
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_USE_CUDA=1 3: $ export MV2_SUPPORT_DL=1 4: 5: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 6: python tf_cnn_benchmarks.py --model=resnet50 \ 7: --variable_update=horovod 8:
For more details, please refer to our HiDL User Guide.
7.4. Example use of LD_PRELOAD
Some cases may require LD_PRELOAD to be set to the path of the MVAPICH2 library. This should be limited to cases where the application uses an interpreter such as python to load the CUDA library.
Try setting LD_PRELOAD if you find the MVAPICH2 fails when using your CUDA device buffers in MPI calls.
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_GPUDIRECT_GDRCOPY_LIB=/path/to/GDRCOPY/install/lib64/libgdrapi.so 3: $ export MV2_USE_CUDA=1 4: 5: $ $MV2_PATH/bin/mpirun_rsh -n 4 hostA hostA hostB hostB \ 6: LD_PRELOAD=$MV2_PATH/lib/libmpi.so hoomd lj_liquid_bmark.hoomd
When Jsrun launcher is used on IBM OpenPOWER systems such as Summit and Sierra, please add the MVAPICH2 library path to OMPI_LD_PRELOAD_PREPEND.
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_GPUDIRECT_GDRCOPY_LIB=/path/to/GDRCOPY/install/lib64/libgdrapi.so 3: $ export MV2_USE_CUDA=1 4: $ export LD_LIBRARY_PATH=/path/to/pmi4pmix/lib:$LD_LIBRARY_PATH 5: $ export OMPI_LD_PRELOAD_PREPEND=$MV2_PATH/lib/libmpi.so 6: 7: $ jsrun -n2 ./osu_latency D D
8. Compile time and run-time check for CUDA-aware support
Since MVAPICH2 2.3.5, a compile-time macro MPIX_CUDA_AWARE_SUPPORT and a run-time function MPIX_Query_cuda_support() have been added to determine whether CUDA-aware primitives are supported or not. To access them, you need to include mpi-ext.h similar to OpenMPI. A sample program of using these checks can be found in https://www.open-mpi.org/faq/?category=runcuda#mpi-cuda-aware-support.
9. Supported Configurations
Below is the list of currently supported configurations. In order to select the GPU, the application is free to use any selection method. For HCA, the parameters that are required have to exported as shown below. Note that MVAPICH2-GDR 2.3.7 does automatically and dynamically the best binding by default, and prints a warning if the user does specify a binding which is not the best mapping. See CPU Binding and Mapping Parameters for more information.
9.1. Single GPU / Single HCA
With single HCA, the default example shown earlier will work fine since there is no HCA selection involved for Single HCA configurations.
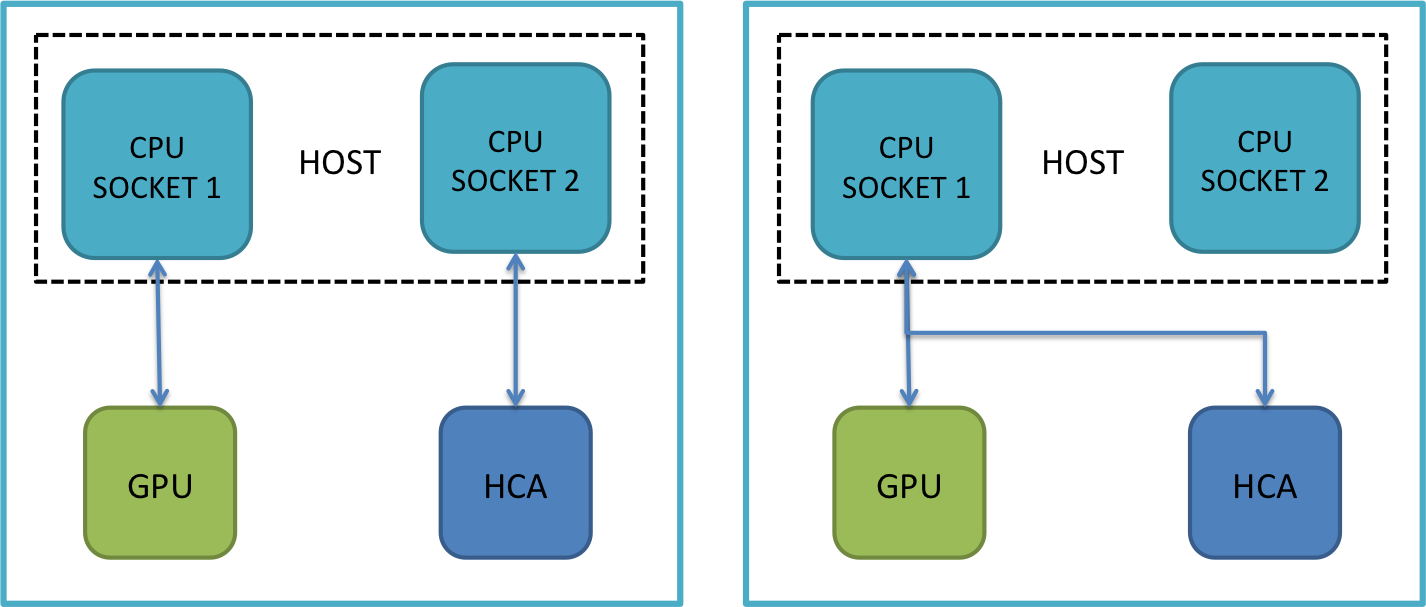
9.2. Single GPU / Multiple HCA
As mentioned earlier, MVAPICH2-GDR 2.3.7 will automatically tries to take advantage of the multirail configuration for small and large message sizes. Note that if one HCA is far from the GPU (different sockets), then the default multirail selection might affect the performance. Thus, please do an explicit HCA selection, selecting the nearest as the first HCA In order to explicitly select the near HCA, please use MV2_IBA_HCA or MV2_PROCESS_TO_RAIL_MAPPING parameter.
$ export MV2_PROCESS_TO_RAIL_MAPPING=mlx5_0:mlx5_1 $ or $ export MV2_IBA_HCA=mlx5_0:mlx5_1
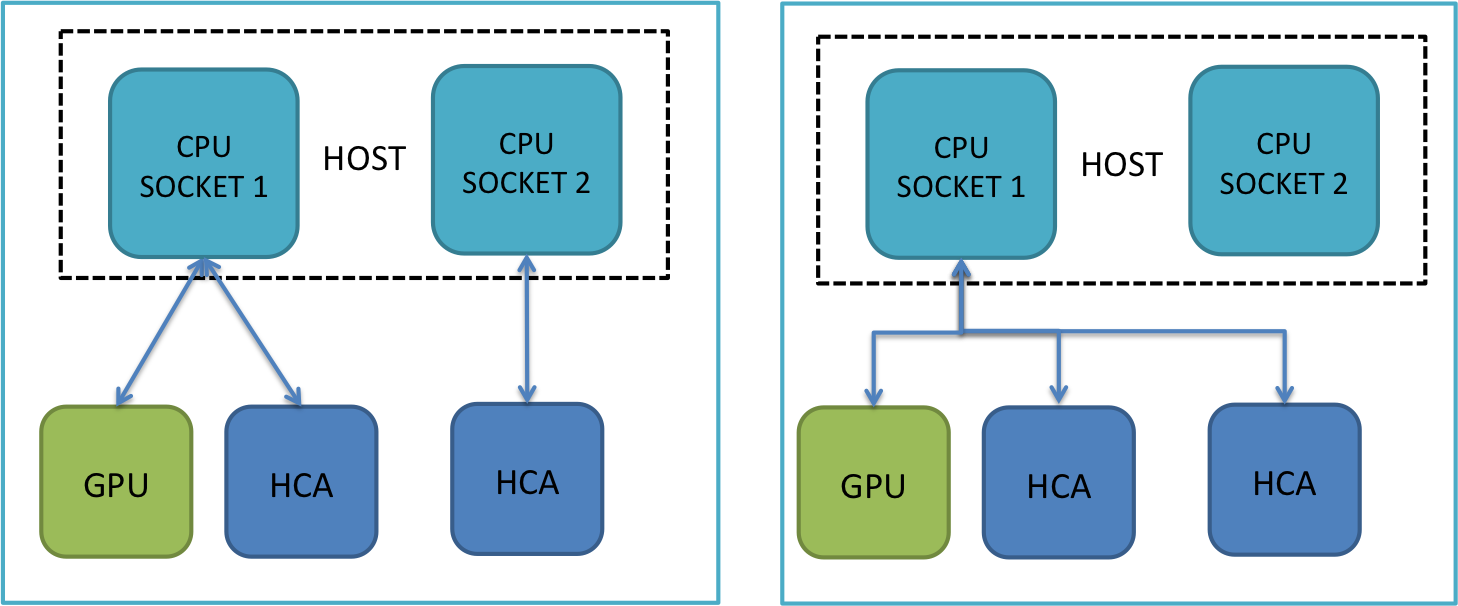
9.3. Multiple GPU / Single HCA
For this configuration, users can use same parameters as Single GPU / Single
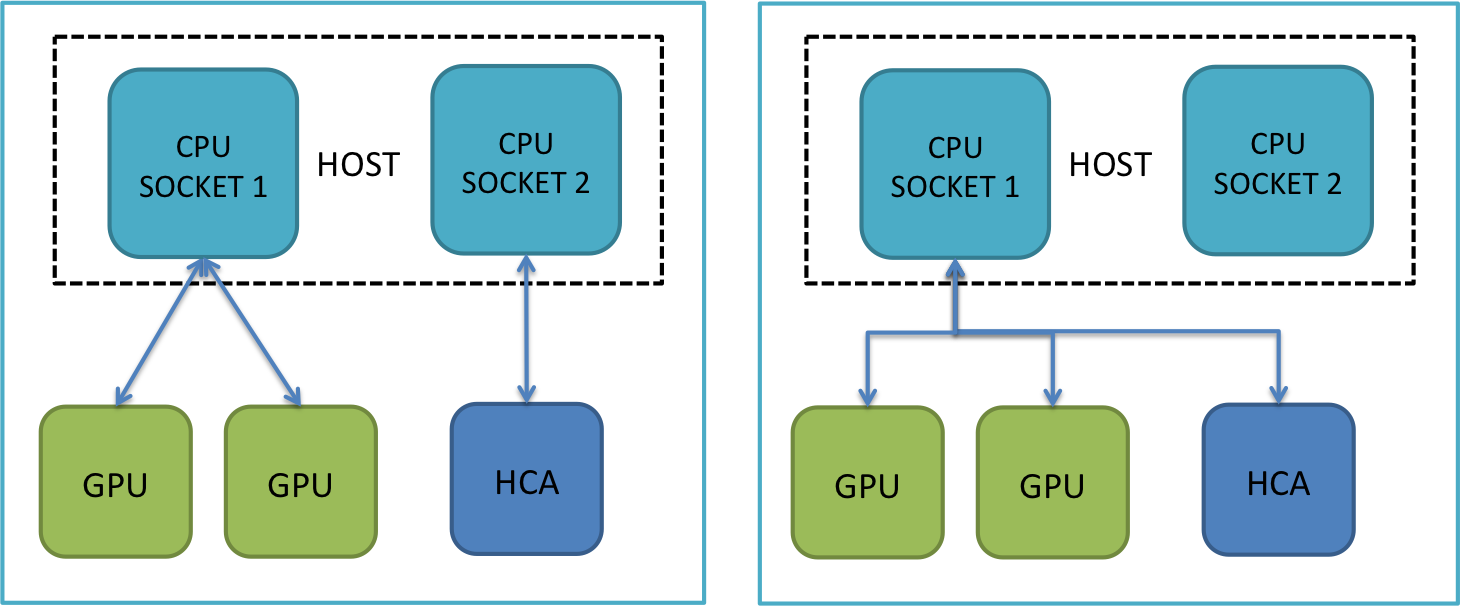
9.4. Multiple GPU / Multiple HCA
By default MVAPICH2-GDR 2.3.7 will automatically select the HCA near to the GPU select by the process and bind that process to a core on the same socket. Further, as MVAPICH2-GDR supports the dynamic initialization of the CUDA devices, the HCA re-selection is transparently and dynamically performed. The parameters below are an explicit setting to the same default setting.
$ export MV2_RAIL_SHARING_POLICY=FIXED_MAPPING $ export MV2_PROCESS_TO_RAIL_MAPPING=mlx5_0:mlx5_1 $ or $ export MV2_IBA_HCA=mlx5_0:mlx5_1
9.5. Examples using OSU micro-benchmarks with multi-rail support
To run the osu_bw test with multi-rail support, use the following command.
$ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu $ export MV2_GPUDIRECT_GDRCOPY_LIB= path to the GDRCOPY install $ export MV2_USE_CUDA=1 $ export MV2_PROCESS_TO_RAIL_MAPPING=mlx5_0:mlx5_1 $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ $MV2_PATH/libexec/mvapich2/get_local_rank \ $MV2_PATH/libexec/mvapich2/osu_bw -d cuda (or -d rocm for AMD GPUs)
For more information about running OSU micro-benchmarks to measure MPI Multiple GPU / Multiple HCA : 2 GPUs and 2 HCAs in Different Sockets] communication performance on NVIDIA GPU clusters, please refer to:
10. Enabling Support on GPU-Clusters using regular OFED (without GPUDirect RDMA)
Targeted for GPU-based Systems that do not support GPUDirect RDMA feature: A) Use regular OFED instead of Mellanox OFED (MOFED) and B) Use older GPUs that do not support GPUDirect RDMA feature.
For such systems, MVAPICH2-GDR 2.3.7 efficiently takes advantage of CUDA IPC and GDRCOPY features. Please download and install the appropriate package.
11. Enabling Support for Managed Memory (NVIDIA GPUs only)
Managed Memory feature provides high productivity in developing CUDA kernels by allowing the same memory allocation (pointer) to be used on both CPU and GPU. To enable this productivity for distributed memory programming, MVAPICH2-GDR 2.3.7 provides CUDA-Aware MPI support with manged memory allocation. In other words, MPI calls can be directly performed on managed memory buffers. Further, it allows mixing different memory allocations in a single application. For instance one can perform a send operation from a managed memory buffer and receive it on a buffer allocated directly on the GPU memory.
To enable this feature, please set MV2_CUDA_ENABLE_MANAGED=1 when executing your application.
MVAPICH2-GDR 2.3.7 enhances the intra-node support for managed memory when all GPUs in a node are peer-access. The design takes advantage of CUDA-IPC to boost the performance of data movement operations from/to managed buffers. To enable this feature, please add MV2_CUDA_MANAGED_IPC=1 on your execution command line.
12. Enabling Support for InfiniBand hardware UD-Multicast based collectives (NVIDIA GPUs only)
InfiniBand hardware UD-Multicast (IB-MCAST) is a feature for designing highly scalable collective operations. Combining IB-MCAST and other features in MVAPICH2-GDR is extremely helpful for high-performance streaming applications, which are using MPI_Bcast.
This feature is disabled by default. Basic support for IB-MCAST feature with MVAPICH2-GDR can be enabled by using following parameters. Please refer to MVAPICH2 User Guide for more details.
-
MV2_USE_MCAST
-
Default: 0
-
Set this to 1, to enable hardware multicast support in collective communication
-
-
MV2_USE_RDMA_CM_MCAST
-
Default: 0
-
Set this to 1, to enable RDMA-CM-based hardware multicast support in collective communication
-
-
MV2_MCAST_NUM_NODES_THRESHOLD
-
Default: 8
-
This defines the threshold for enabling multicast support in collective communication. When MV2_USE_MCAST is set to 1 and the number of nodes in the job is greater than or equal to the threshold value, it uses multicast support in collective communication.
-
In addition to the basic support, advanced features can be enabled by using the following parameters:
-
MV2_GPUDIRECT_MCAST_PIPELINE
-
Default: 1 (Enabled)
-
To disable the support for efficient pipelined IB-MCAST from NVIDIA GPUs, set to 0.
-
-
MV2_GPUDIRECT_MCAST_RECV_TYPE
-
Default: 1 (Basic support)
-
To toggle support for IB-MCAST from/to NVIDIA GPUs. For enabling efficient zero-copy design, set to 2.
-
-
MV2_MCAST_RELIABILITY_TYPE
-
Default: 1 (Negative acknowledgement-based scheme)
-
To toggle reliability support for UD-based IB-MCAST from/to NVIDIA GPUs. For enabling RMA-based reliability scheme, set to 2.
-
13. Tuning and Usage Parameters
Note that MVAPICH2-GDR selects the optimal value for each of the following parameters based on architecture detection.
13.1. Basic Usage
Unless explicitly mentioned, all the following environment variables are applicable to
both CUDA and ROCm versions of MVAPICH2-GDR-
MV2_USE_CUDA
-
Default: 0 (Disabled)
-
To toggle support for communication from NVIDIA GPUs. For enabling, set to 1.
-
Applicable: NVIDIA GPUs only
-
-
MV2_USE_ROCM
-
Default: 0 (Disabled)
-
To toggle support for communication from AMD GPUs. For enabling, set to 1.
-
Applicable: AMD GPUs only
-
-
MV2_USE_GPUDIRECT_RDMA
-
Default: 1 (Enabled)
-
The runtime variable MV2_USE_GPUDIRECT will be deprecated in future. Please use MV2_USE_GPUDIRECT_RDMA or MV2_USE_GDR to enable/disable the GPU Direct RDMA support in MVAPICH2. Please note that disabling this feature only disables the GPU Direct RDMA support. Other features of the GPU Direct family like GPU Direct Peer-to-Peer (P2P) communication are not affected by this parameter.
-
-
MV2_CUDA_BLOCK_SIZE
-
Default: 262144
-
To tune pipelined internode transfers between NVIDIA GPUs. Higher values may help applications that use larger messages and are bandwidth critical.
-
-
MV2_GPUDIRECT_LIMIT
-
Default: 8192
-
To tune the hybrid design that uses pipelining and GPUDirect RDMA for maximum performance while overcoming P2P bandwidth bottlenecks seen on modern systems. GPUDirect RDMA is used only for messages with size less than or equal to this limit. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
-
MV2_USE_GPUDIRECT_RECEIVE_LIMIT
-
Default: 131072
-
To tune the hybrid design that uses pipelining and GPUDirect RDMA for maximum performance while overcoming P2P read bandwidth bottlenecks seen on modern systems. Lower values (16384) may help improve performance on nodes with multiple GPUs and IB adapters. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
-
MV2_CUDA_IPC_THRESHOLD
-
Default: 32768
-
To tune the usage of IPC communication path for intranode configuration. Note that if you have processes sharing the same GPU, please increase this parameter to a higher value like 524288.
-
-
MV2_CUDA_USE_IPC_BCAST
-
Default: 0 (Disabled)
-
To toggle support for IPC-based intra-node broadcast among NVIDIA GPUs. For enabling, set to 1.
-
13.2. Additional Parameters
The following parameters are required in some specific use-cases. Here we will
explain these additional parameters and when to use them.-
MV2_USE_LAZY_MEM_UNREGISTER
-
Default: 1 (Default behavior of IB registration cache)
-
For host buffers created by CUDA/ROCm APIs e.g., cudaMallocHost / hipMallocHost, it is observed that the same virtual address (VA) is returned after few iterations. If this buffer had been registered with IB and cached in IB registration cache, then we have to evict the stale entries upon free’ing. While this is already taken care of in normal scenario where host buffers are allocated with malloc/mmap calls, it becomes a special case where the host buffer is allocated by device APIs. In order to circumvent the invalidation issues, we recomment setting the value of this variable to to 2.
-
1: $ export MV2_USE_LAZY_MEM_UNREGISTER=2
13.3. Running on OpenPOWER Systems
-
MV2_USE_GPUDIRECT_RDMA
-
Default: 1
-
Current generation (POWER8) systems do not have GPUDirect RDMA support so users should disable this support by setting MV2_USE_GPUDIRECT_RDMA=0
-
There are no expected side effects when GPUDIRECT support is disabled.
-
13.4. GDRCOPY Feature
-
MV2_GDRCOPY_LIMIT
-
Default: 8192
-
The runtime variable MV2_USE_GPUDIRECT_GDRCOPY_LIMIT will be deprecated in future. Please use MV2_GDRCOPY_LIMIT to tune the local transfer threshold using gdrcopy module between GPU and CPU for point to point communications. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
-
MV2_GDRCOPY_NAIVE_LIMIT
-
Default: 8192
-
The runtime variable MV2_USE_GPUDIRECT_GDRCOPY_NAIVE_LIMIT will be deprecated in future. Please use MV2_GDRCOPY_NAIVE_LIMIT to tune the local transfer threshold using gdrcopy module between GPU and CPU for collective communications. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
13.5. Loopback Feature
-
MV2_USE_GPUDIRECT_LOOPBACK_LIMIT
-
Default: 8192
-
To tune the transfer threshold using loopback design for point to point communications. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
-
MV2_USE_GPUDIRECT_LOOPBACK_NAIVE_LIMIT
-
Default: 8192
-
To tune the transfer threshold using loopback design for collective communications. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
13.6. Non-Blocking Collective Support with GDR and Core-Direct
-
MV2_USE_CORE_DIRECT
-
Default: 0
-
To turn ON this features please set it to 1
-
To enable efficient support while working around the P2P bottleneck please set to 2
-
To provide a maximal overlap for both CPU and GPU simultaneous computing while avoiding the P2P bottlenecks set to 3
-
Applicable: NVIDIA GPUs
-
13.7. CPU Binding and Mapping Parameters
When experimenting on nodes with multiple NVIDIA GPUs and InfiniBand adapters, selecting the right NVIDIA GPU and IB adapter at each MPI process can be important to achieve good performance. The following parameters help uses bind processes to different IB HCAs. GPU device selection is expected to be made in the application using CUDA interfaces like cudaSetDevice. For the IB selection we have the below scenarios :
1) Multi-IB and Multi-GPU scenario: on a systems with 2 IBs and 2 GPUs, achieving the best best performance requires the processes to use the GPU closest to the IB. To do so:
-
MV2_PROCESS_TO_RAIL_MAPPING
-
Default: NONE
-
Value Domain: BUNCH, SCATTER, <CUSTOM LIST>
-
When MV2_RAIL_SHARING_POLICY is set to the value FIXED_MAPPING this variable decides the manner in which the HCAs will be mapped to the rails. The<CUSTOM LIST> is colon(:) separated list with the HCA ranks (e.g. 0:1:1:0) or HCA names specified (e.g. mlx5_0:mlx5_1:mlx5_0:mlx5_1). For more information on this parameter, refer to following section of MVAPICH2 user guide: http://mvapich.cse.ohio-state.edu/static/media/mvapich/mvapich2-userguide.html#x1-22200011.40
-
2) Multi-IB and 1 GPU scenario : for this scenario and in order to take advantage of the Multi-rails support, sending a large message from/to a GPU will take advantage of both IBs. In addition to the MV2_PROCESS_TO_RAIL_MAPPING parameter, the following parameters can be used:
-
MV2_RAIL_SHARING_POLICY
-
Default: ROUND_ROBIN
-
Value Domain: USE_FIRST, ROUND_ROBIN, FIXED_MAPPING
-
This specifies the policy that will be used to assign HCAs to each of the processes. For more information on this parameter, refer to following section of MVAPICH2 user guide: http://mvapich.cse.ohio-state.edu/static/media/mvapich/mvapich2-userguide.html#x1-22000011.38
-
-
MV2_RAIL_SHARING_LARGE_MSG_THRESHOLD
-
Default: 16K
-
This specifies the message size beyond which striping of messages across all available rails will take place.
-
It is also important to bind MPI processes as close to the GPU and IB adapter as possible. The following parameter allows you to manually control process-to-core mapping. MVAPICH2-GDR 2.3.7 does automatically the best binding by default, and prints a warning if the user does specify a binding which is not the best mapping.
-
MV2_CPU_MAPPING
-
Default: Unset
-
This allows users to specify process to CPU (core) mapping. The detailed usage of this parameter is described in MVAPICH2 user guide
-
13.8. GPU Datatype Processing Feature
These features are only supported for NVIDIA GPUs for now.
-
MV2_CUDA_DIRECT_DT_THRESHOLD
-
Default: 8
-
To tune the direct transfer scheme using asynchronous CUDA memory copy for datatype packing/unpacking. Direct transfer scheme can avoid the kernel invocation overhead for dense datatypes. It has to be tuned based on the node architecture, the processor, the GPU and the IB card.
-
-
MV2_CUDA_KERNEL_VECTOR_TIDBLK_SIZE
-
Default: 1024
-
To tune the thread block size for vector/hvector packing/unpacking kernels. It has to be tuned based on the vector/hvector datatype shape and the GPU.
-
-
MV2_CUDA_KERNEL_VECTOR_YSIZE
-
Default: 32
-
To tune the x dimension of thread block for vector/hvector packing/unpacking kernels. This value is automatically tuned based on the block length of vector/hvector datatypes. It also can be tuned based on the vector/hvector datatype shape and the GPU.
-
-
MV2_CUDA_KERNEL_SUBARR_TIDBLK_SIZE
-
Default: 1024
-
To tune the thread block size for subarray packing/unpacking kernels. It has to be tuned based on the subarray datatype dimension, shape and the GPU.
-
-
MV2_CUDA_KERNEL_SUBARR_XDIM
-
Default: 8 (3D) /16 (2D) /256 (1D)
-
To tune the x dimension of thread block for subarray packing/unpacking kernels. It has to be tuned based on the subarray datatype dimension, shape and the GPU.
-
-
MV2_CUDA_KERNEL_SUBARR_YDIM
-
Default: 8 (3D) /32 (2D) /4 (1D)
-
To tune the y dimension of thread block for subarray packing/unpacking kernels. It has to be tuned based on the subarray datatype dimension, shape and the GPU.
-
-
MV2_CUDA_KERNEL_SUBARR_ZDIM
-
Default: 16 (3D) /1 (2D) /1 (1D)
-
To tune the z dimension of thread block for subarray packing/unpacking kernels. It has to be tuned based on the subarray datatype dimension, shape and the GPU.
-
-
MV2_CUDA_KERNEL_ALL_XDIM
-
Default: 16
-
To tune the x dimension of thread block for all datatypes except vector/hvector, indexed_block/hindexed_block and subarray. It has to be tuned based on the datatype shape and the GPU.
-
-
MV2_CUDA_KERNEL_IDXBLK_XDIM
-
Default: 1
-
To tune the x dimension of thread block for indexed_block/hindexed_block packing/unpacking kernels.It has to be tuned based on the indexed_block/hindexed_block datatype shape and the GPU.
-
-
MV2_USE_SHM_CACHE_DATATYPE
-
Default: 1
-
To toggle support for caching the layout of MPI derived datatype. For disabling, set to 0.
-
-
MV2_USE_ZCPY_DDT
-
Default: 1
-
To toggle support for performing zero-copy datatype procesing between GPUs through PCIe or NVLink. For disabling, set to 0.
-
-
MV2_CUDA_USE_DDT_KERNEL_FUSION
-
Default: 1
-
To toggle support for performing GPU-driven datatype procesing with kernel fusion feature for low-latency packing/unpacking. For disabling, set to 0.
-
-
MV2_CUDA_USE_DDT_ASYNC_KERNEL
-
Default: 1
-
To toggle support for performing asynchronous GPU-driven datatype procesing. For disabling, set to 0.
-
14. GPU-Aware MPI Primitives
The following GPU aware MPI primitives are available for both CUDA and ROCM stacks as a part of the library:
-
Point to Point
-
MPI_Send, MPI_Recv, MPI_Isend, MPI_Irecv, MPI_Ssend, MPI_Rsend, MPI_Issend, MPI_Bsend, MPI_Sendrecv, MPI_Send_init, MPI_Recv_init, MPI_Ssend_init, MPI_Bsend_init, MPI_Rsend_init
-
-
Collectives
-
MPI_Bcast, MPI_Scatter, MPI_Scatterv, MPI_Gather, MPI_Gatherv, MPI_Reduce, MPI_Allreduce, MPI_Allgather, MPI_Allgatherv, MPI_Alltoall, MPI_Alltoallv, MPI_Scan, MPI_Exscan, MPI_Reduce_scatter, MPI_Reduce_scatter_block
-
-
Non-Blocking Collectives (NBC)
-
MPI_Ibcast, MPI_Iscatter, MPI_Igather, MPI_Iallgather, MPI_Ialltoall
-
-
One Sided Communications
[True one sided implementation for transfers from/to GPU]
- Allocation Primitives
-
-
MPI_Win_create, MPI_Win_allocate, MPI_Win_allocate_shared, MPI_Win_create_dynamic
-
- Communication Primitives
-
-
MPI_Get, MPI_Put, MPI_Accumulate
-
- Synchronization Primitives
-
-
MPI_Win_lock/MPI_Win_unlock, MPI_Win_lock_all/MPI_Win_unlock_all, MPI_Win_flush, MPI_Win_fence, MPI_Win_flush_all, MPI_Win_flush_local, MPI_Win_flush_local_all, MPI_Win_post/MPI_Win_start/MPI_Win_wait/MPI_Win_complete
-
-
Enhanced support of MPI datatypes for GPU
-
MPI_Type_vector, MPI_Type_hvector, MPI_Type_create_struct, MPI_Type_create_subarray, MPI_Type_indexed, MPI_Type_hindexed, MPI_Type_create_hindexed_block
-
15. CUDA and OpenACC Extensions to OMB
The following benchmarks have been extended to evaluate performance of MPI communication from and to buffers on NVIDIA GPU devices.
|
osu_bibw
|
Bidirectional Bandwidth Test |
|
osu_bw
|
Bandwidth Test |
|
osu_latency
|
Latency Test |
|
osu_put_latency
|
Latency Test for Put |
|
osu_get_latency
|
Latency Test for Get |
|
osu_put_bw
|
Bandwidth Test for Put |
|
osu_get_bw
|
Bandwidth Test for Get |
|
osu_put_bibw
|
Bidirectional Bandwidth Test for Put |
|
osu_acc_latency
|
Latency Test for Accumulate |
|
osu_cas_latency
|
Latency Test for Compare and Swap |
|
osu_fop_latency
|
Latency Test for Fetch and Op |
|
osu_allgather
|
MPI_Allgather Latency Test |
|
osu_allgatherv
|
MPI_Allgatherv Latency Test |
|
osu_allreduce
|
MPI_Allreduce Latency Test |
|
osu_alltoall
|
MPI_Alltoall Latency Test |
|
osu_alltoallv
|
MPI_Alltoallv Latency Test |
|
osu_bcast
|
MPI_Bcast Latency Test |
|
osu_gather
|
MPI_Gather Latency Test |
|
osu_gatherv
|
MPI_Gatherv Latency Test |
|
osu_reduce
|
MPI_Reduce Latency Test |
|
osu_reduce_scatter
|
MPI_Reduce_scatter Latency Test |
|
osu_scatter
|
MPI_Scatter Latency Test |
|
osu_scatterv
|
MPI_Scatterv Latency Test |
|
osu_iallgather
|
MPI_Iallgather Latency and Overlap Test |
|
osu_iallgatherv
|
MPI_Iallgatherv Latency and Overlap Test |
|
osu_iallreduce
|
MPI_Iallreduce Latency and Overlap est |
|
osu_ialltoall
|
MPI_Ialltoall Latency and Overlap Test |
|
osu_ialltoallv
|
MPI_Ialltoallv Latency and Overlap Test |
|
osu_ibcast
|
MPI_Ibcast Latency and Overlap Test |
|
osu_igather
|
MPI_Igather Latency and Overlap Test |
|
osu_igatherv
|
MPI_Igatherv Latency and Overlap Test |
|
osu_iscatter
|
MPI_Iscatter Latency and Overlap Test |
|
osu_iscatterv
|
MPI_Iscatterv Latency and Overlap Test |
Some directions for usage are:
-
The CUDA extensions are enabled when the benchmark suite is configured with --enable-cuda option.
-
The OpenACC extensions are enabled when --enable-openacc is specified. Whether a process allocates its communication buffers on the GPU device or on the host can be controlled at run-time.
-
Each of the pt2pt benchmarks takes two input parameters. The first parameter indicates the location of the buffers at rank 0 and the second parameter indicates the location of the buffers at rank 1. The value of each of these parameters can be either H or D to indicate if the buffers are to be on the host or on the device respectively. When no parameters are specified, the buffers are allocated on the host.
-
The collective benchmarks will use buffers allocated on the device if the -d option is used otherwise the buffers will be allocated on the host.
-
The non-blocking collective benchmarks can also use -t for MPI_Test() calls and -r option for setting the target of dummy computation.
16. Managed Memory Extensions to OMB
In addition to the CUDA and OpenACC support, the following benchmarks provides the support for managed memory allocation. To enable this support, set the environment variable mentioned earlier. This will enable support in the MVAPICH runtime. This is currently not supported for AMD GPUs. To enable allocation of memory using the CUDA managed memory API, refer below.
-
For pt2pt operations use the M flag
-
For collective operations use the -d managed flag
16.1. Example running OSU Micro Benchmarks with Managed Memory Support
To run osu_latency test for measuring internode MPI Send/Recv latency between GPUs, when enabling managed memory allocations on both the sender and receiver.
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_GPUDIRECT_GDRCOPY_LIB=/path/to/GDRCOPY/install 3: $ export MV2_USE_CUDA=1 4: $ export MV2_CUDA_ENABLE_MANAGED=1 5: 6: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 7: $MV2_PATH/libexec/mvapich2/get_local_rank \ 8: $MV2_PATH/libexec/mvapich2/osu_latency M M
For collectives, see the example below
1: $ export MV2_PATH=/opt/mvapich2/gdr/2.3.7/gnu 2: $ export MV2_GPUDIRECT_GDRCOPY_LIB=/path/to/GDRCOPY/install 3: $ export MV2_USE_CUDA=1 4: $ export MV2_CUDA_ENABLE_MANAGED=1 5: 6: $ $MV2_PATH/bin/mpirun_rsh -export -np 2 hostA hostB \ 7: $MV2_PATH/libexec/mvapich2/get_local_rank \ 8: $MV2_PATH/libexec/mvapich2/osu_bcast -d managed
The following benchmarks have been extended to evaluate performance of MPI Communications to and from buffers allocated with CUDA Managed memory.
|
osu_bibw
|
Bidirectional Bandwidth Test |
|
osu_bw
|
Bandwidth Test |
|
osu_latency
|
Latency Test |
|
osu_allgather
|
MPI_Allgather Latency Test |
|
osu_allgatherv
|
MPI_Allgatherv Latency Test |
|
osu_allreduce
|
MPI_Allreduce Latency Test |
|
osu_alltoall
|
MPI_Alltoall Latency Test |
|
osu_alltoallv
|
MPI_Alltoallv Latency Test |
|
osu_bcast
|
MPI_Bcast Latency Test |
|
osu_gather
|
MPI_Gather Latency Test |
|
osu_gatherv
|
MPI_Gatherv Latency Test |
|
osu_reduce
|
MPI_Reduce Latency Test |
|
osu_reduce_scatter
|
MPI_Reduce_scatter Latency Test |
|
osu_scatter
|
MPI_Scatter Latency Test |
|
osu_scatterv
|
MPI_Scatterv Latency Test |
17. Container Support
MVAPICH2-GDR can be run on the Docker container environments. In this section, we use Docker as the example to show how to set up the network environment for it.
-
Prerequisites:
-
Docker: https://www.docker.com/
-
Nvidia Docker: https://github.com/NVIDIA/nvidia-docker
-
The following script can be used as a best practice to configure Docker container network, please edit it according to your environment
1: # This script should be executed with root privilege 2: 3: # Launch Docker container using nvidia-docker with your image 4: # Please refer to https://github.com/nvidia/nvidia-docker/wiki for more information 5: 6: # Set a hostname and assign an IP address to the launched container, in this example 7: docker_hostname="docker-cont1" 8: docker_ip="192.168.3.99" 9: 10: # Configure network for the Docker container 11: ifname="eth0p1" 12: cpid=`nvidia-docker inspect --format '' "$docker_hostname"` 13: 14: # Create a macvlan interface associated with your physical interface 15: ip link add $ifname link eth0 type macvlan mode bridge 16: 17: # Add this interface to the container's network namespace 18: ip link set netns $cpid $ifname 19: 20: # Bring up the link 21: nsenter -t $cpid -n ip link set $ifname up 22: 23: # And configure the ip address and routing 24: nsenter -t $cpid -n ip addr add $docker_ip/24 dev $ifname 25: 26: # Start ssh daemon 27: nvidia-docker exec $docker_hostname /usr/sbin/sshd 28: 29: # Now you can attach to the Docker container and then install and run the MVAPICH2-GDR there
