|
|
MVAPICH2-X 2.3 User Guide
MVAPICH Team
Network-Based Computing Laboratory
Department of Computer Science and Engineering
The Ohio State University
http://mvapich.cse.ohio-state.edu
Copyright (c) 2001-2021
Network-Based Computing Laboratory,
headed by Dr. D. K. Panda.
All rights reserved.
Last revised: September 22, 2021
Message Passing Interface (MPI) has been the most popular programming model for developing parallel scientific applications. Partitioned Global Address Space (PGAS) programming models are an attractive alternative for designing applications with irregular communication patterns. They improve programmability by providing a shared memory abstraction while exposing locality control required for performance. It is widely believed that hybrid programming model (MPI+X, where X is a PGAS model) is optimal for many scientific computing problems, especially for exascale computing.
MVAPICH2-X provides advanced MPI features/support (such as User Mode Memory Registration (UMR), On-Demand Paging (ODP), Dynamic Connected Transport (DC), Core-Direct, SHARP, and XPMEM). It also provides support for the OSU InfiniBand Network Analysis and Monitoring (OSU INAM) Tool.
It also provides a unified high-performance runtime that supports both MPI and PGAS programming models on InfiniBand clusters. It enables developers to port parts of large MPI applications that are suited for PGAS programming model. This minimizes the development overheads that have been a huge deterrent in porting MPI applications to use PGAS models. The unified runtime also delivers superior performance compared to using separate MPI and PGAS libraries by optimizing use of network and memory resources. The DCT support is also available for the PGAS models.
MVAPICH2-X supports Unified Parallel C (UPC) OpenSHMEM, CAF, and UPC++ as PGAS models. It can be used to run pure MPI, MPI+OpenMP, pure PGAS (UPC/OpenSHMEM/CAF/UPC++) as well as hybrid MPI(+OpenMP) + PGAS applications. MVAPICH2-X derives from the popular MVAPICH2 library and inherits many of its features for performance and scalability of MPI communication. It takes advantage of the RDMA features offered by the InfiniBand interconnect to support UPC/OpenSHMEM/CAF/UPC++ data transfer and OpenSHMEM atomic operations. It also provides a high-performance shared memory channel for multi-core InfiniBand clusters.
|
|
The MPI implementation of MVAPICH2-X is based on MVAPICH2, which supports MPI-3 features. The UPC implementation is UPC Language Specification 1.2 standard compliant and is based on Berkeley UPC 2.20.2 . OpenSHMEM implementation is OpenSHMEM 1.3 standard compliant and is based on OpenSHMEM Reference Implementation 1.3 . CAF implementation is Coarray Fortran Fortran 2015 standard compliant and is based on UH CAF Reference Implementation 3.0.39 .
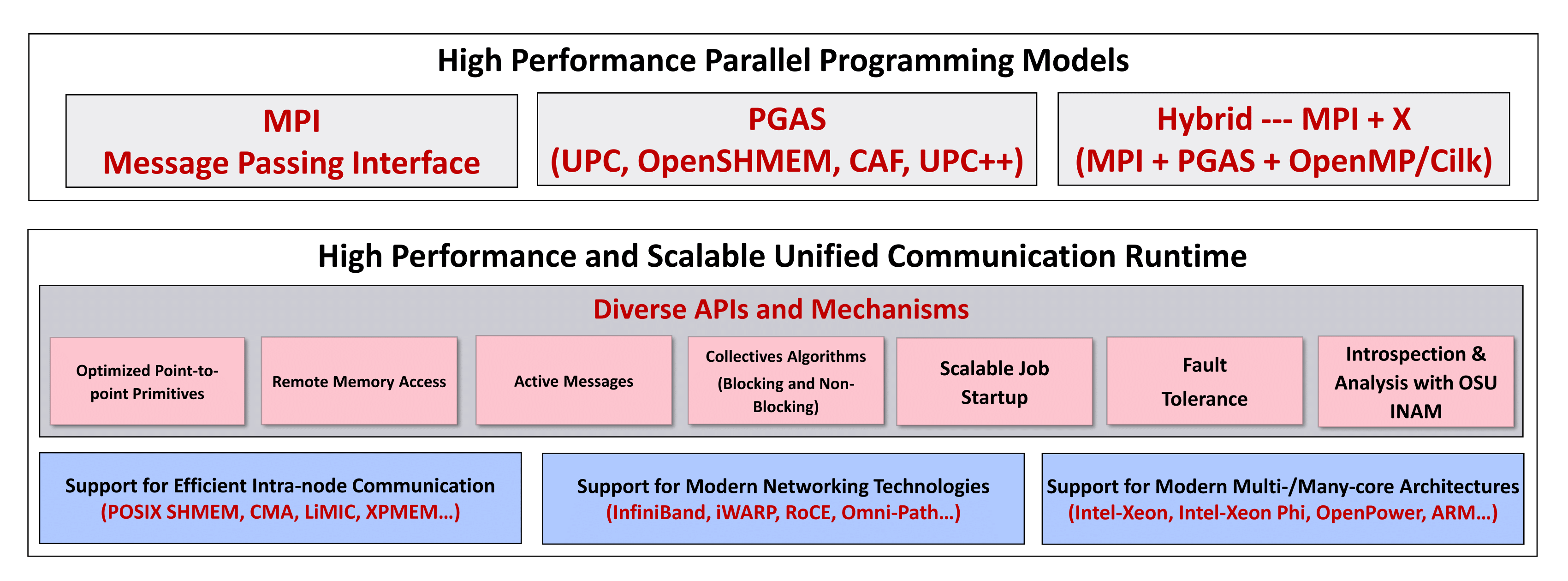
The current release supports InfiniBand transport interface (inter-node), and Shared Memory Interface (intra-node). The overall architecture of MVAPICH2-X is shown in the Figure 1.
This document contains necessary information for users to download, install, test, use, tune and troubleshoot MVAPICH2-X 2.3. We continuously fix bugs and update this document as per user feedback. Therefore, we strongly encourage you to refer to our web page for updates.
MVAPICH2-X supports pure MPI programs, MPI+OpenMP programs, UPC programs, OpenSHMEM programs, CAF programs, UPC++ programs, as well as hybrid MPI(+OpenMP) + PGAS(UPC / OpenSHMEM / CAF / UPC++) programs. Current version of MVAPICH2-X 2.3 supports UPC, OpenSHMEM, CAF and UPC++ as the PGAS model. High-level features of MVAPICH2-X 2.3 are listed below. New features compared to 2.2 are indicated as (NEW).
MPI Features
(NEW) MPI Advanced Features
Unified Parallel C (UPC) Features
OpenSHMEM Features
CAF Features
UPC++ Features
Hybrid Program Features
Unified Runtime Features
Support for OSU InfiniBand Network Analysis and Management (OSU INAM) Tool v0.9.5
The MVAPICH2-X package can be downloaded from here. Select the link for your distro. All MVAPICH2-X RPMs are relocatable.
Below are the steps to download MVAPICH2-X RPMs:
Running the install.sh script will install the software in /opt/mvapich2-x. The /opt/mvapich2-x/ directory contains the software built using gcc distributed with RHEL7 and RHEL6. The install.sh script runs the near equivalent of the following command:
rpm -Uvh --nodeps *.rpm
This will upgrade any prior versions of MVAPICH2-X that may be present. These RPMs are relocatable and advanced users may skip the install.sh script to directly use alternate commands to install the desired RPMs.
By default, MVAPICH2-X UPC uses the online UPC-to-C translator as the Berkeley UPC does. If your
install environment cannot access the Internet, upcc will not work. In this situation, a local
translator should be installed. The local Berkeley UPC-to-C translator can be downloaded
from http://upc.lbl.gov/download/. After installing it, you should edit the upcc configure file
(/opt/mvapich2-x/gnu/etc/upcc.conf or $HOME/.upccrc), and set the translator option to be the
path of the local translator
(e.g. /usr/local/berkeley_upc_translator-<VERSION>/targ).
The CAF implementation of MVAPICH2-X is based on the OpenUH CAF compiler. Thus an installation of OpenUH compiler is needed. Here are the detailed steps to build CAF support in MVAPICH2-X:
Installing OpenUH Compiler
Installing MVAPICH2-X CAF
Copy the libcaf directory from MVAPICH2-X into OpenUH
MVAPICH2-X can be installed using Spack without building it from source. See the MVAPICH2 Spack userguide for details.
MVAPICH2-X supports MPI applications, PGAS (OpenSHMEM, UPC, CAF, UPC++) applications and
hybrid (MPI+ OpenSHMEM, MPI+UPC, MPI+CAF or MPI+UPC++) applications. User should choose
the corresponding compilers according to the applications. These compilers (oshcc, upcc, uhcaf, upc++
and mpicc) can be found under <MVAPICH2-X_INSTALL>
/bin folder.
Please use mpicc for compiling MPI and MPI+OpenMP applications. Below are examples to build MPI applications using mpicc:
$ mpicc -o test test.c
This command compiles test.c program into binary execution file test by mpicc.
$ mpicc -fopenmp -o hybrid mpi_openmp_hybrid.c
This command compiles a MPI+OpenMP program mpi_openmp_hybrid.c into binary execution file hybrid by mpicc, when MVAPICH2-X is built with GCC compiler. For Intel compilers, use -openmp instead of -fopenmp; For PGI compilers, use -mp instead of -fopenmp.
Below is an example to build an MPI, an OpenSHMEM or a hybrid application using oshcc:
$ oshcc -o test test.c
This command compiles test.c program into binary execution file test by oshcc.
For MPI+OpenMP hybrid programs, add compile flags -fopenmp, -openmp or -mp according to different compilers, as mentioned in mpicc usage examples.
Below is an example to build a UPC or a hybrid MPI+UPC application using upcc:
$ upcc -o test test.c
This command compiles test.c program into binary execution file test by upcc.
Note: (1) The UPC compiler generates the following warning if MPI symbols are found in source
code.
upcc: warning: ’MPI_*’ symbols seen at link time: should you be using
’--uses-mpi’ This warning message can be safely ignored.
(2) upcc requires a C compiler as the back-end, whose version should be as same as the compiler used by MVAPICH2-X libraries. Take the MVAPICH2-X RHEL7 GCC RPMs for example, the C compiler should be GCC 4.8.5. You need to install this version of GCC before using upcc.
Below is an example to build an MPI, a CAF or a hybrid application using uhcaf:
Download the UH test example
Compilation using uhcaf
To take advantage of MVAPICH2-X, user needs to specify the MVAPICH2-X as the conduit during the compilation.
Below is an example to build a UPC++ or a hybrid MPI+UPC++ application using upc++:
$ upc++ -o test test.cpp
This command compiles test.cpp program into binary execution file test by upc++.
(2) In order to use complete set of features provided by UPC++, a C++ compiler is required as the back-end, whose version should be as same as the compiler used by MVAPICH2-X libraries. Take the MVAPICH2-X RHEL7 GCC RPMs for example, the C compiler should be GCC 4.8.5. You need to install this version of GCC before using upc++.
This section provides instructions on how to run applications with MVAPICH2. Please note that on new multi-core architectures, process-to-core placement has an impact on performance. MVAPICH2-X inherits its process-to-core binding capabilities from MVAPICH2. Please refer to (MVAPICH2 User Guide) for process mapping options on multi-core nodes.
The MVAPICH team suggests users using this mode of job start-up. mpirun_rsh provides fast and scalable job start-up. It scales to multi-thousand node clusters. It can be use to launch MPI, OpenSHMEM, UPC, CAF and hybrid applications.
Prerequisites:
Jobs can be launched using mpirun_rsh by specifying the target nodes as part of the command as shown below:
$ mpirun_rsh -np 4 n0 n0 n1 n1 ./test
This command launches test on nodes n0 and n1, two processes per node. By default ssh is used.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 ./test
This command launches test on nodes n0 and n1, two processes per each node using rsh instead of ssh. The target nodes can also be specified using a hostfile.
$ mpirun_rsh -np 4 -hostfile hosts ./test
The list of target nodes must be provided in the file hosts one per line. MPI or OpenSHMEM ranks are assigned in order of the hosts listed in the hosts file or in the order they are passed to mpirun_rsh. i.e., if the nodes are listed as n0 n1 n0 n1, then n0 will have two processes, rank 0 and rank 2; whereas n1 will have rank 1 and 3. This rank distribution is known as “cyclic”. If the nodes are listed as n0 n0 n1 n1, then n0 will have ranks 0 and 1; whereas n1 will have ranks 2 and 3. This rank distribution is known as “block”.
The mpirun_rsh hostfile format allows users to specify a multiplier to reduce redundancy. It also allows users to specify the HCA to be used for communication. The multiplier allows you to save typing by allowing you to specify blocked distribution of MPI ranks using one line per hostname. The HCA specification allows you to force an MPI rank to use a particular HCA. The optional components are delimited by a ‘:’. Comments and empty lines are also allowed. Comments start with ‘#’ and continue to the next newline. Below are few examples of hostfile formats:
Many parameters of the MPI library can be configured at run-time using environmental variables. In order to pass any environment variable to the application, simply put the variable names and values just before the executable name, like in the following example:
$ mpirun_rsh -np 4 -hostfile hosts ENV1=value ENV2=value ./test
Note that the environmental variables should be put immediately before the executable. Alternatively, you may also place environmental variables in your shell environment (e.g. .bashrc). These will be automatically picked up when the application starts executing.
MVAPICH2-X provides oshrun and can be used to launch applications as shown below.
$ oshrun -np 2 ./test
This command launches two processes of test on the localhost. A list of target nodes where the processes should be launched can be provided in a hostfile and can be used as shown below. The oshrun hostfile can be in one of the two formats outlined for mpirun_rsh earlier in this document.
$ oshrun -f hosts -np 2 ./test
MVAPICH2-X provides upcrun to launch UPC and MPI+UPC applications. To use upcrun, we suggest users to set the following environment:
$ export MPIRUN_CMD=’<path-to-MVAPICH2-X-install>/bin/mpirun_rsh -np %N -hostfile hosts %P %A’
A list of target nodes where the processes should be launched can be provided in the hostfile named as “hosts”. The hostfile “hosts” should follow the same format for mpirun_rsh, as described in Section 4.2.1. Then upcrun can be used to launch applications as shown below.
$ upcrun -n 2 ./test
Similar to UPC and OpenSHMEM, to run a CAF application, we can use cafrun or mpirun_rsh:
To run a UPC++ application we need mpirun_rsh:
MVAPICH2-X also distributes the Hydra process manager along with with mpirun_rsh. Hydra can be used either by using mpiexec or mpiexec.hydra. The following is an example of running a program using it:
$ mpiexec -f hosts -n 2 ./test
This process manager has many features. Please refer to the following web page for more details.
http://wiki.mcs.anl.gov/mpich2/index.php/Using_the_Hydra_Process_Manager
Support for the User Mode Memory Registration of InfiniBand is available for Mellanox ConnectIB (Dual-FDR) and ConnectX-4 (EDR) adapters. This features requires Mellanox OFED version 2.4 (or higher) and supported IB HCAs listed above. Note that users should be using the appropriate version of the MVAPICH2-X RPM built with the support for advanced features to use this. Please refer to Section 8.2 of the userguide for a detailed description of the UMR related runtime parameters.
This command launches test on nodes n0 and n1, two processes per node with support for User Mode Memory Registration.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_UMR=1 ./test
Support for the Dynamic Connected transport of InfiniBand is available for Mellanox ConnectIB (Dual-FDR) and ConnectX-4 (EDR) adapters. This features requires Mellanox OFED version 2.4 (or higher) and supported IB HCAs listed above. It also automatically enables the Shared Receive Queue (SRQ) feature available in MVAPICH2-X. Note that users should be using the appropriate version of the MVAPICH2-X RPM built with the support for advanced features to use this. Please refer to Section 8.1 of the userguide for a detailed description of the DC related runtime parameters.
This command launches test on nodes n0 and n1, two processes per node with support for Dynamic Connected Transport.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_DC=1 ./test
This command launches test on nodes n0 and n1, two processes per node with support for Dynamic Connected Transport with different number of DC initiator objects for small messages and large messages.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_DC=1 MV2_SMALL_MSG_DC_POOL=10 MV2_LARGE_MSG_DC_POOL=10 ./test
The Mellanox ConnectX and ConnectIB series of InfiniBand HCAs provides support for offloading entire collective communication operations. These features are exposed to the user through the interfaces provided in the latest Mellanox OFED drivers. MVAPICH2-X takes advantage of such capabilities to provide hardware based offloading support for MPI-3 non-blocking collective operations. This allows for better computation and communication overlap for MPI and hybrid MPI+PGAS applications. MVAPICH2-X 2.3 offers Core-Direct based support for the following collective operations - MPI_Ibcast, MPI_Iscatter, MPI_Iscatterv, MPI_Igather, MPI_Igatherv, MPI_Iallgather, MPI_Iallgatherv, MPI_Ialltoall, MPI_Ialltoallv, MPI_Ialltoallw, and MPI_Ibarrier. Note that users should be using the appropriate version of the MVAPICH2-X RPM built with the support for advanced features to use this. Please refer to Section 8.9 of the userguide for a detailed description of the Core-Direct related runtime parameters.
The Core-Direct feature and can be enabled or disabled globally by the use of the environment variable MV2_USE_CORE_DIRECT.
This command launches test on nodes n0 and n1, two processes per node with support for Core-Direct based non-blocking collectives.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_CORE_DIRECT=1 ./test
By default, when Core-Direct capabilities are turned on using the above variable, all supported non-blocking collectives listed above leverage the feature. To specifically toggle Core-Direct capabilities on a per collective basis, the following environment variables may be used:
This command launches test on nodes n0 and n1, two processes per node with Core-Direct based non-blocking collectives support for all non-blocking collectives listed above except non-blocking broadcast.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_CORE_DIRECT=1 MV2_USE_CD_IBCAST=0 ./test
The OSU InfiniBand Network Analysis and Monitoring tool - OSU INAM monitors IB clusters in real time by querying various subnet management entities in the network. It is also capable of interacting with the MVAPICH2-X software stack to gain insights into the communication pattern of the application and classify the data transferred into Point-to-Point, Collective and Remote Memory Access (RMA). OSU INAM can also remotely monitoring the CPU utilization of MPI processes in conjunction with MVAPICH2-X. Note that users should be using the appropriate version of the MVAPICH2-X RPM built with the support for advanced features to use this. In this section, we detail how one should enable MVAPICH2-X to work in conjunction with OSU INAM.
Please note that MVAPICH2-X must be launched with support for on-demand connection management when running in conjunction with OSU INAM. One can achieve this by setting the MV2_ON_DEMAND_THRESHOLD environment variable to a value less than the number of processes in the job.
Please refer to the Tools page in the MVAPICH website (http://mvapich.cse.ohio-state.edu/tools/osu-inam) for more information on how to download, install and run OSU INAM. Please refer to Section 8.8 of the userguide for a detailed description of the OSU INAM related runtime parameters.
This command launches test on nodes n0 and n1, two processes per node with support for sending the process and node level information to the OSU INAM daemon.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_ON_DEMAND_THRESHOLD=1 MV2_TOOL_INFO_FILE_PATH=/opt/inam/.mv2-tool-mvapich2.conf ./test
MVAPICH2-X supports shared address-space based efficient MPI intra-node communication. This feature requires XPMEM https://gitlab.com/hjelmn/xpmem kernel module. Currently, it provides support for efficient intra-node rendezvous communication and zero-copy MPI collective operations. Note that the users should be using the appropriate version of the MVAPICH2-X RPM built with the support for XPMEM to use this. Please refer to Section 8.10.1 and Section 8.11.1 of the userguide for a detailed description of the XPMEM based point-to-point and collective communication support in MVAPICH2-X.
XPMEM kernels module can be installed by following the instructions given below:
The following command launches osu_latency with two MPI processes on a single node and uses XPMEM based rendezvous communication mechanism.
$ mpirun_rsh -np 2 n0 n1 MV2_SMP_USE_XPMEM=1 ./osu_latency
The following command launches osu_reduce on nodes n0 and n1, two processes per node with support for XPMEM based MPI_Reduce for message sizes greater than 4KB.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_USE_XPMEM_COLL=1 MV2_XPMEM_COLL_THRESHOLD=4096 ./osu_reduce
Note: XPMEM has a known issue where a remote memory segment that is “attached” using XPMEM, can not be registered with InfiniBand device. In some cases, if severe performance degradation is observed when using XPMEM based collectives, additionally setting following two parameters can circumvent the issue.
MV2_IBA_EAGER_THRESHOLD=262144 MV2_VBUF_TOTAL_SIZE=262144
MVAPICH2-X provides an optimized asynchronous progress to overlap computation and communication in HPC applications. This design is recommended over thread-based asynchronous progress design in MPICH. The optimized asynchronous progress design enables applications to use all available cores for compute without sparing dedicated cores for asynchronous progress threads. Applications which use large (greater than eager threshold) non-blocking messages are suggested to use asynchronous progress design to gain better overlap of computation and communication.
The optimized version of asynchronous communication progress design is enabled by using environment variable MV2_OPTIMIZED_ASYNC_PROGRESS=1. Note that the optimized support needs the user to enable basic asynchronous progress support by setting MV2_ASYNC_PROGRESS=1.
This command launches test on nodes n0 and n1, two processes per node with support for Asynchronous Progress design.
$ mpirun_rsh -rsh -np 4 n0 n0 n1 n1 MV2_ASYNC_PROGRESS=1 MV2_OPTIMIZED_ASYNC_PROGRESS=1 MV2_CPU_BINDING_POLICY=hybrid ./test
In MVAPICH2, support for SHArP-based collectives has been enabled for MPI applications running over OFA-IB-CH3 interface. Currently, this support is available for the following collective operations:
This feature is turned off by default at runtime and can be turned on at runtime by using parameter MV2_ENABLE_SHARP=1 ( 8.13.1).
Note that the various SHArP related daemons (SHArP Aggregation Manager - sharpam and the local SHArP daemon - sharpd must be installed, setup and running for SHArP support in MVAPICH2 to work properly. This can be verified by running the sharp_hello program available in the “bin” sub-folder of the SHArP installation directory.
When using HPCX v1.7, we recommend setting SHARP_COLL_ENABLE_GROUP_TRIM=0 environment variable. Note that if you are using mpirun_rsh you need to add -export option to make sure that environment variable is exported correctly. This environment variable is a part of SHArP library. Please refer to SHArP userguide for more information.
MVAPICH2-X supports hybrid programming models. Applications can be written using both MPI and PGAS constructs. Rather than using a separate runtime for each of the programming models, MVAPICH2-X supports hybrid programming using a unified runtime and thus provides better resource utilization and superior performance.
A simple example of Hybrid MPI+OpenSHMEM program is shown below. It uses both MPI and OpenSHMEM constructs to print the sum of ranks of each processes.
start_pes in line 10 initializes the runtime for MPI and OpenSHMEM communication. An explicit call to MPI_Init is not required. The program uses MPI calls MPI_Comm_rank and MPI_Comm_size to get process rank and size, respectively (lines 14-15). MVAPICH2-X assigns same rank for MPI and PGAS model. Thus, alternatively the OpenSHMEM constructs _my_pe and _num_pes can also be used to get rank and size, respectively. In line 17, every process does a barrier using OpenSHMEM construct shmem_barrier_all.
After this, every process does a fetch-and-add of the rank to the variable sum in process 0. The sample program uses OpenSHMEM construct shmem_int_fadd (line 21) for this. Following the fetch-and-add, every process does a barrier using MPI_Barrier (line 24). Process 0 then broadcasts sum to all processes using MPI_Bcast (line 27). Finally, all processes print the variable sum. Explicit MPI_Finalize is not required.
The program outputs the following for a four-process run:
The above sample hybrid program is available at <MVAPICH2-X_INSTALL>/<gnu|intel>/share
/examples/hybrid_mpi_shmem.c
A simple example of Hybrid MPI+UPC program is shown below. Similarly to the previous example, it uses both MPI and UPC constructs to print the sum of ranks of each UPC thread.
An explicit call to MPI_Init is not required. The program uses MPI calls MPI_Comm_rank and MPI_Comm_size to get process rank and size, respectively (lines 11-12). MVAPICH2-X assigns same rank for MPI and PGAS model. Thus, MYTHREAD and THREADS contains the UPC thread rank and UPC thread size respectively, which is equal to the return value of MPI_Comm_rank and MPI_Comm_size. In line 15, every UPC thread does a barrier using UPC construct upc_barrier.
After this, every UPC thread set its MPI rank to one element of a global shared memory array A and this element A[MYTHREAD] has affinity with the UPC thread who set the value of it (line 18). Then a local pointer need to be set to the global shared array element for MPI collective functions. Then every UPC thread does a barrier using MPI_Barrier (line 22). After the barrier, MPI_Allreduce is called (line 25) to sum up all the rank values and return the results to every UPC thread, in sum variable. Finally, all processes print the variable sum. Explicit MPI_Finalize is not required.
The program can be compiled using upcc:
The program outputs the following for a four-process run:
The above sample hybrid program is available at <MVAPICH2-X_INSTALL>/<gnu|intel>/share
/examples/hybrid_mpi_upc.c
A simple example of Hybrid MPI+UPC++ program is shown below. Similarly to the previous example, it uses both MPI and UPC++ constructs to reduce the sum of ranks of each UPC++ thread on all ranks. The sum will be reduced on all ranks but printed only on thread 0.
An explicit call to MPI_Init is not required. However, a call to UPC++’s init is required as in line 9. The program uses MPI calls MPI_Comm_rank and MPI_Comm_size to get process rank and size, respectively (lines 16-17). MVAPICH2-X assigns same rank for MPI and PGAS model. Thus, myrank() and ranks() contains the UPC++ thread rank and UPC++ thread size respectively, which is equal to the return value of MPI_Comm_rank and MPI_Comm_size. In line 20, every UPC++ thread does a barrier by explicitly calling UPC++ function barrier().
After this, every UPC++ thread sets its MPI rank to one element of a global shared memory array A and this element A[myrank()] has affinity with the UPC++ thread who set the value of it (line 23). Then a local pointer need to be set to the global shared array element for MPI collective functions. Then every UPC++ thread does a barrier using MPI_Barrier (line 29). After the barrier, MPI_Allreduce is called (line 32) to sum up all the rank values and return the results to every UPC++ thread, in sum variable. Finally, all processes print the variable sum. Explicit MPI_Finalize is not required. However, UPC++’s finalize() function is called in the end for graceful termination of UPC++ application (line 39).
The program can be compiled using upc++:
The program outputs the following for a four-process run:
The above sample hybrid program is available at <MVAPICH2-X_INSTALL>/<gnu|intel>/share
/examples/hybrid_mpi_upcxx.c
We have extended the OSU Micro Benchmark (OMB) suite with tests to measure performance of OpenSHMEM operations. OSU Micro Benchmarks (OMB-5.6.2) have OpenSHMEM data movement and atomic operation benchmarks. The complete benchmark suite is available along with MVAPICH2-X binary package, in the folder: <MVAPICH2-X_INSTALL>/libexec/osu-micro-benchmarks. A brief description for each of the newly added benchmarks is provided below.
Put Latency (osu_oshm_put):
This benchmark measures latency of a shmem_putmem operation for different data sizes. The user is required to select whether the communication buffers should be allocated in global memory or heap memory, through a parameter. The test requires exactly two PEs. PE 0 issues shmem_putmem to write data at PE 1 and then calls shmem_quiet. This is repeated for a fixed number of iterations, depending on the data size. The average latency per iteration is reported. A few warm-up iterations are run without timing to ignore any start-up overheads. Both PEs call shmem_barrier_all after the test for each message size.
Get Latency (osu_oshm_get):
This benchmark is similar to the one above except that PE 0 does a shmem_getmem operation to read data from PE 1 in each iteration. The average latency per iteration is reported.
Put Operation Rate (osu_oshm_put_mr):
This benchmark measures the aggregate uni-directional operation rate of OpenSHMEM Put between pairs of PEs, for different data sizes. The user should select for communication buffers to be in global memory and heap memory as with the earlier benchmarks. This test requires number of PEs to be even. The PEs are paired with PE 0 pairing with PE n/2 and so on, where n is the total number of PEs. The first PE in each pair issues back-to-back shmem_putmem operations to its peer PE. The total time for the put operations is measured and operation rate per second is reported. All PEs call shmem_barrier_all after the test for each message size.
Atomics Latency (osu_oshm_atomics):
This benchmark measures the performance of atomic fetch-and-operate and atomic operate routines supported in OpenSHMEM for the integer datatype. The buffers can be selected to be in heap memory or global memory. The PEs are paired like in the case of Put Operation Rate benchmark and the first PE in each pair issues back-to-back atomic operations of a type to its peer PE. The average latency per atomic operation and the aggregate operation rate are reported. This is repeated for each of fadd, finc, add, inc, cswap and swap routines.
Collective Latency Tests:
OSU Microbenchmarks consists of the following collective latency tests:
The latest OMB Version includes the following benchmarks for various OpenSHMEM collective operations (shmem_collect, shmem_fcollect shmem_broadcast, shmem_reduce and shmem_barrier).
These benchmarks work in the following manner. Suppose users run the osu_oshm_broadcast benchmark with N processes, the benchmark measures the min, max and the average latency of the shmem_broadcast operation across N processes, for various message lengths, over a number of iterations. In the default version, these benchmarks report average latency for each message length. Additionally, the benchmarks the following options:
OSU Microbenchmarks extensions include UPC benchmarks also. Current version (OMB-5.6.2) has benchmarks for upc_memput and upc_memget. The complete benchmark suite is available along with MVAPICH2-X binary package, in the folder: <MVAPICH2-X_INSTALL>/libexec/osu-micro-benchmarks. A brief description for each of the benchmarks is provided below.
Put Latency (osu_upc_memput):
This benchmark measures the latency of upc_put operation between multiple UPC threads. In this benchmark, UPC threads with ranks less than (THREADS/2) issue upc_memput operations to peer UPC threads. Peer threads are identified as (MYTHREAD+THREADS/2). This is repeated for a fixed number of iterations, for varying data sizes. The average latency per iteration is reported. A few warm-up iterations are run without timing to ignore any start-up overheads. All UPC threads call upc_barrier after the test for each message size.
Get Latency (osu_upc_memget):
This benchmark is similar as the osu_upc_put benchmark that is described above. The difference is that the shared string handling function is upc_memget. The average get operation latency per iteration is reported.
Collective Latency Tests:
OSU Microbenchmarks consists of the following collective latency tests:
The latest OMB Version includes the following benchmarks for various UPC collective operations (upc_all_barrier, upc_all_broadcast, upc_all_exchange, upc_all_gather, upc_all_gather_all, upc_all_reduce, and upc_all_scatter).
These benchmarks work in the following manner. Suppose users run the osu_upc_all_broadcast with N processes, the benchmark measures the min, max and the average latency of the upc_all_broad-cast operation across N processes, for various message lengths, over a number of iterations. In the default version, these benchmarks report average latency for each message length. Additionally, the benchmarks the following options:
In order to provide performance measurement of UPC++ operations, we have also extended OSU Microbenchmarks to include UPC++ based point-to-point and collectives benchmarks. These are included in current version of OMB (OMB-5.6.2). The point-to-point benchmarks include upcxx_async_copy_put and upcxx_async_copy_get. The complete benchmark suite is available along with MVAPICH2-X binary package, in the folder: <MVAPICH2-X_INSTALL>/libexec/osu-micro-benchmarks. A brief description for each of the benchmarks is provided below.
Put Latency (osu_upcxx_async_copy_put):
This benchmark measures the latency of async_copy (memput) operation between multiple UPC++ threads. In this benchmark, UPC++ threads with ranks less than (ranks()/2) copy data ‘from’ their local memory ‘to’ their peer thread’s memory using async_copy operation. By changing the src and dst buffers in async_copy, we can mimic the behavior of upc_memput and upc_memget. Peer threads are identified as (myrank()+ranks()/2). This is repeated for a fixed number of iterations, for varying data sizes. The average latency per iteration is reported. A few warm-up iterations are run without timing to ignore any start-up overheads. All UPC++ threads call barrier() function after the test for each message size.
Get Latency (osu_upcxx_async_copy_get):
Similar to osu_upcxx_async_copy_put, this benchmark mimics the behavior of upc_memget and measures the latency of async_copy (memget) operation between multiple UPC++ threads. The only difference is that the src and dst buffers in async_copy are swapped. In this benchmark, UPC++ threads with ranks less than (ranks()/2) copy data ‘from’ their peer thread’s memory ‘to’ their local memory using async_copy operation. The rest of the details are same as discussed above. The average get operation latency per iteration is reported.
Collective Latency Tests:
OSU Microbenchmarks consists of the following collective latency tests:
The latest OMB Version includes the following benchmarks for various UPC++ collective operations (upcxx_reduce, upcxx_bcast, upcxx_gather, upcxx_allgather, upcxx_alltoall, upcxx_scatter).
These benchmarks work in the following manner. Suppose users run the osu_upcxx_bcast with N processes, the benchmark measures the min, max and the average latency of the upcxx_bcast operation across N processes, for various message lengths, over a number of iterations. In the default version, these benchmarks report average latency for each message length. Additionally, the benchmarks the following options:
MVAPICH2-X supports all the runtime parameters of MVAPICH2 (OFA-IB-CH3). A comprehensive list of all runtime parameters of MVAPICH2 2.3 can be found in User Guide. Runtime parameters specific to MVAPICH2-X are listed below.
MVAPICH2-X features support for the Dynamic Connected (DC) transport protocol from Mellanox. In this section, we specify some of the runtime parameters that control these advanced features.
Enable the use of the Dynamic Connected (DC) InfiniBand transport.
This parameter must be same across all processes that wish to communicate with each other in a job.
Controls the number of DC receive communication objects. Please note that we have extensively tuned this parameter based on job size and communication characteristics.
Controls the number of DC send communication objects used for transmitting small messages. Please note that we have extensively tuned this parameter based on job size and communication characteristics.
Controls the number of DC send communication objects used for transmitting large messages. Please note that we have extensively tuned this parameter based on job size and communication characteristics.
MVAPICH2-X provides support for the User Mode Memory Registration (UMR) feature from Mellanox. In this section, we specify some of the runtime parameters that control these advanced features.
Enable the use of User Mode Memory Registration (UMR) for high performance datatype based communication.
Controls the number of pre-created UMRs for non-contiguous data transfer.
MVAPICH2-X features support for the Core-Direct (CD) collective offload interface from Mellanox. In this section, we specify some of the runtime parameters that control these advanced features.
Enables core-direct support for non-blocking collectives.
Enables tuned version of core-direct support for non-blocking collectives that prioritizes overlap and latency based on message size.
Enables core-direct support for non-blocking Allgather collective.
Enables core-direct support for non-blocking Allgatherv collective.
Enables core-direct support for non-blocking Alltoall collective.
Enables core-direct support for non-blocking Alltoallv collective.
Enables core-direct support for non-blocking Alltoallw collective.
Enables core-direct support for non-blocking Barrier collective.
Enables core-direct support for non-blocking Broadcast collective.
Enables core-direct support for non-blocking Gather collective.
Enables core-direct support for non-blocking Gatherv collective.
Enables core-direct support for non-blocking Scatter collective.
Enables core-direct support for non-blocking Scatterv collective.
MVAPICH2-X features support for the On Demand Paging (ODP) feature from Mellanox. In this section, we specify some of the runtime parameters that control these advanced features.
Enable the use of On-Demand Paging for inter-node communication
Enable verbs-level prefetch operation to speed-up On-demand Paging based inter-node communication
MVAPICH2-X features support for contention-aware, kernel-assisted blocking collectives using Cross Memory Attach (CMA). These designs are applicable to the following interfaces: OFA-IB-CH3, OFA-IB-RoCE, PSM-CH3, and PSM2-CH3. In this section, we specify some of the runtime parameters that control this feature.
Enables support for CMA collectives.
Specifies the message size above which CMA collectives are used.
Enables CMA collective support for Allgather.
Enables CMA collective support for Alltoall.
Enables CMA collective support for Gather.
Enables CMA collective support for Scatter.
Set UPC Shared Heap Size
Enable/Disable shared memory scheme for intra-node communication.
Set OpenSHMEM Symmetric Heap Size
Enable/Disable CMA based intra-node communication design
Specifies the path to the file containing the runtime parameters to enable node level, job level and process level data collection for MVAPICH2-X. This file contains the following parameters MV2_TOOL_QPN, MV2_TOOL_LID, MV2_TOOL_REPORT_CPU_UTIL and MV2_TOOL_COUNTER_INTERVAL.
Specifies the UD QPN at which OSU INAM is listening.
Specifies the IB LID at which OSU INAM is listening.
Specifies whether MVAPICH2-X should report process level CPU utilization information.
Specifies whether MVAPICH2-X should report process level memory utilization information.
Specifies whether MVAPICH2-X should report process level I/O utilization information.
Specifies whether MVAPICH2-X should report process to node communication information. This parameter only takes effect for multi-node runs.
Specifies the interval at which MVAPICH2-X should report node, job and process level information.
MVAPICH2-X features support for the high-performance hierarchical multi-leader collectives designated for multi/many-core processors with Omni-Path or Infiniband network architectures. Currently, MPI_Allreduce collective operation is supported with this feature. In this section, we specify the runtime parameter that controls this advanced feature.
Enables support for hierarchical multi-leader collectives. This feature can be disabled by setting this parameter to 0.
MVAPICH2-X provides support for XPMEM based intra-node communication channel to achieve direct load/store based inter-process communication in MPI. This feature is designated for multi/many-core processors with Infiniband network architectures and available for the OFA-IB-CH3 and OFA-RoCE-CH3 channels.. In this section, we specify the runtime parameter that controls this advanced feature.
Enables support for XPMEM based intra-node communication. This feature can be disabled by setting this parameter to 0.
MVAPICH2-X features support for the high-performance shared-address-space based multi-leader collectives, enabled via load/store semantics, targeting modern multi/many-core processors. Currently, MPI_Reduce and MPI_Allreduce operations are supported with multi-leader design while MPI_Bcast, MPI_Scatter, MPI_Gather, and MPI_Allgather collectives are supported using heirarchical designs e.g., direct load/store for intra-node phase and best tuned algorithm for inter-node. These are available for OFA-IB-CH3, OFA-RoCE-CH3, PSM-CH3, and PSM2-CH3 channels. In this section, we specify the runtime parameter that controls these advanced features.
Enables support for shared address-space (XPMEM) based collectives. This variable enables and disables all the XPMEM collectives. This feature can be disabled by setting this parameter to 0.
This threshold sets the value in bytes after which all the XPMEM collectives are used. The threshold values for each collective are set based on the architecture-specific tuning (typically same as eager to rendezvous switchover threshold). Setting this variable will override the thresholds set for individual collectives and use this value instead as the new threshold for all the XPMEM collectives.
MVAPICH2-X features support of Asynchronous Communication Progress. In this section, we specify some of the runtime parameters that control these advanced features.
Enables use of the basic asynchronous communication progress scheme.
Enables use of optimized asynchronous communication progress scheme.
MVAPICH2-X supports SHArP-based collectives for MPI applications running over OFA-IB-CH3 interface. In this section, we specify some of the runtime parameters that control these advanced features.
Set this to 1, to enable hardware SHArP support in collective communication
By default, this is set by the MVAPICH2 library. However, you can explicitly set the HCA name which is realized by the SHArP library.
By default, this is set by the MVAPICH2 library. However, you can explicitly set the HCA port which is realized by the SHArP library.
Based on our experience and feedback we have received from our users, here we include some of the problems a user may experience and the steps to resolve them. If you are experiencing any other problem, please feel free to contact us by sending an email to mvapich-help@cse.ohio-state.edu.
Current version of upcc available with MVAPICH2-X package gives a compilation error if the gcc version is not 4.4.7. Please install gcc version 4.4.7 to fix this.
By default, upcc compiler driver will transparently use Berkeley’s HTTP-based public UPC-to-C translator during compilation. If your system is behind a firewall or not connected to Internet, upcc can become unresponsive. This can be solved by using a local installation of UPC translator, which can be downloaded from here.
The translator can be compiled and installed using the following commands:
$ make
$ make install PREFIX=<translator-install-path>
After this, upcc can be instructed to use this translator.
$ upcc -translator=<translator-install-path> hello.upc -o hello
By default, the symmetric heap in OpenSHMEM is allocated in shared memory. The maximum amount of shared memory in a node is limited by the memory available in /dev/shm. Usually the default system configuration for /dev/shm is 50% of main memory. Thus, programs which specify heap size larger than the total available memory in /dev/shm will give an error. For example, if the shared memory limit is 8 GB, the combined symmetric heap size of all intra-node processes shall not exceed 8 GB.
Users can change the available shared memory by remounting /dev/shm with the desired limit. Alternatively, users can control the heap size using OOSHM_SYMMETRIC_HEAP_SIZE (Section 8.7.2) or disable shared memory by setting OOSHM_USE_SHARED_MEM=0 (Section 8.7.1). Please be aware that setting a very large shared memory limit or disabling shared memory will have a performance impact.
While running UPC++ collectives which require high memory footprints the users may encounter errors stating scratch size limit reached. You can increase the scratch size by exporting following environment variable.
export GASNET_COLL_SCRATCH_SIZE=256M (or higher).
MVAPICH2-X RPMs are relocatable. Please use the --prefix option during RPM installation for installing MVAPICH2-X into a specific location. An example is shown below:
$ rpm -Uvh --prefix <specific-location> mvapich2-x_gnu-2.2-0.3.rc2.el7.centos.x86_64.rpm openshmem-osu_gnu-2.2-0.2.rc2.el7.centos.x86_64.rpm berkeley_upc-osu_gnu-2.2-0.2.rc2.el7.centos.x86_64.rpm berkeley_upcxx-osu_gnu-2.2-0.1.rc2.el7.centos.x86_64.rpm osu-micro-benchmarks_gnu-5.3-1.el7.centos.x86_64.rpm
Note: XPMEM has a known issue where a memory region that is attached using XPMEM, can not be registered with InfiniBand device. In some cases, if severe performance degradation is observed when using XPMEM based collectives, additionally setting following two parameters can circumvent the performance degradation.
MV2_IBA_EAGER_THRESHOLD=262144 MV2_VBUF_TOTAL_SIZE=262144